Apache Big Data 2017 Conference in Miami, FL

Thursday, 18 May 2017

I particularly liked the many networking opportunities. This was facilitated by the presence of company booths (see below).



Next, the president of the Apache Foundation, Sam Ruby (@samruby) talked about the state of the society. Click here to watch his talk. At the time of the conference, there were 5,822 committers, 682 members and 181 Project Management Committee members.

Next, Alan F. Gates (@alanfgates, co-founder of Hortonworks) took the stage. He gave a talk titled “Training our team in the Apache way”. See his slides here.



Adam Kocoloski (@kocolosk, IBM fellow) discussed his personal experience in the Apache CouchDB project including the ups and downs.
Then, it was good to shift gears a bit by listening to a psychologist: Dr. Sandra Matz (University of Cambridge).

After the morning break, I attended Trevor Grant (@rawkintrevo, open source evangelist at IBM)’s talk on the status of Apache Mahout.


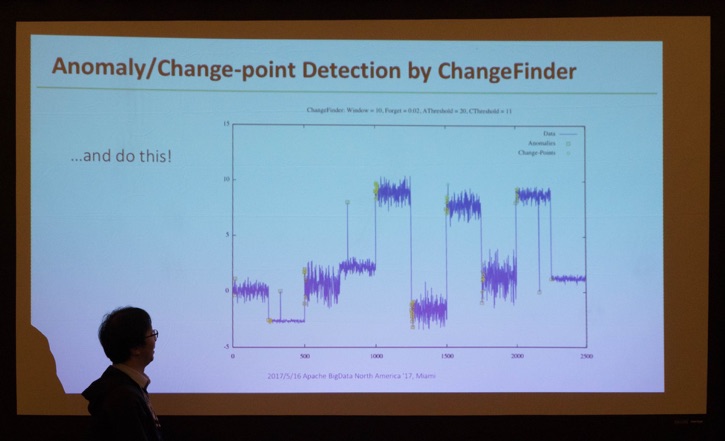
Next, Makoto Yui (@myui) and Takashi Yamamuro (@maropu) took the stage for their talk on presenting the Apache Hivemall project. The inclusion of a few key algorithms make this an interesting project: Detecting anomalies and change points, as well as future inclusions of XGBoost, sparse vector support in RandomForests, ...

Next, I attended Luciano Resende (@lresende1975, IBM’s @apachespark_tc, see pictures below)’s excellent talk on the Apache Bahir project.

Next, ING employees talked about their CoreIntel project (see pictures below). ING set an ambitious goal to have an insight into the overall network data activity. The purpose is to quickly recognize and neutralize unwelcomed guests such as malware, viruses and to prevent data leakage or track down misconfigured software components.


Next, Dominic Divakaruni took the stage with his presentation titled “Scalable Deep Learning with Apache MXNet (@ApacheMXNet).” Click here for the Feathercast audio of the talk.



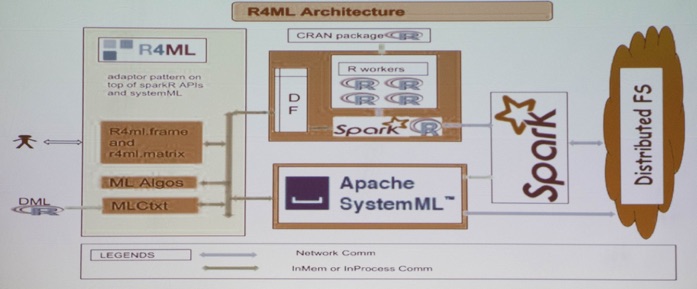
Finally, Alok Singh (IBM’s @apachespark_tc) discussed their interesting R wrapper for @ApacheSystemML for R-based scalable machine learning framework.


The organizers included plenty of networking opportunities, including the celebration of the 18th birthday of The Apache Software Foundation.

Several hundreds of open-source enthusiasts descended to the Intercontinental Hotel in Miami, FL for this year’s @Apachecon as well as the Apache Big Data 2017 conference of the Apache Foundation (@TheASF). Sessions on the first day started with a series of opening keynotes. This is a great event to learn about all the exciting work that is going on in the 300+ Apache Projects. I particularly noticed the many interesting sessions about the Apache Beam Project. Congrats to the organizers (@linuxfoundation and @EventsLF) for setting up such a great event. But let’s now walk through the event chronologically: First, we were welcomed by Rich Bowen (@rbowen, open source evangelist at Red Hat, see picture below).



Next morning, the event started with a plenary panel discussion of venture capitalists on the topic of IoT (Internet of Things). Panel moderator was Roman Shaposhnik (@Pivotal), participants are: Sudip Chakrabarti (@), Abhi Arunachalam (@abhi_VC at @BatteryVentures) and James Pace (Runtime).

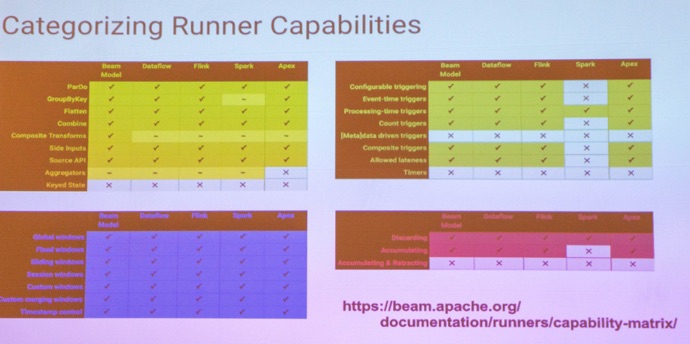
Then, I attended a long series of impressive @ApacheBeam project presentations. This included talks by @dhalperi, @BonaciDavor and @jbonofre.







After the break, I attended an @ApacheApex talk by Devendra Tagare (@datatorrent).



Finally, I decided to end the day with a talk on “Leveraging the GPU on Spark” by Tobias Polzer.

Next morning, I first attended the Apache Rya - a scalable RDF triple store - talk by Adina Crainiceanu (see picture below).

Next up was my own talk titled “Big Data Analytics Using PySpark for Analyzing IPO Tweets (@DirkVandenPoel).”

My own talk was followed by another Ghent University talk by Thomas Vanhove (@TVanhove, @TenguPaaS). He presented the City of Things, a smart city project in the city of Antwerp (Belgium).


Next, I attended a great unscheduled (surprise) talk by Chris Fregly (@cflegly) on High Performance Distributed Tensorflow.


In sum, this is a great event to attend if you want to stay up-to-date about the cool new developments in open source of the Apache Software Foundation. Kudos again to the organizers for a superb event at a great venue! All pictures are copyrighted by yours truly (@DirkVandenPoel).

Finally, I attended the real-estate #analytics presentation by @TenX.



