INFORMS 2015 Annual Meeting in Philadelphia, PA

5,500+ academics and business people gathered in Philadelphia, PA for the biggest analytics and OR event of the year with 79 concurrent sessions: The INFORMS Annual Meeting. This year, the UGent Data Analytics team had five talks at the event, so we were very busy. Central themes at this event included: Analytics, Data Mining, Social Media, Big Data, prescriptive analytics, ... . These topics are directly in line with our analytics programs: MScMA and Business Engineering/Data Analytics.
Long lines at the registration pointed to a well-attended event (see picture below).
Thursday 5 November 2015

This completes my personal report on this great event. We hope to see you next year again at the INFORMS Annual Meeting in Nashville, TN.

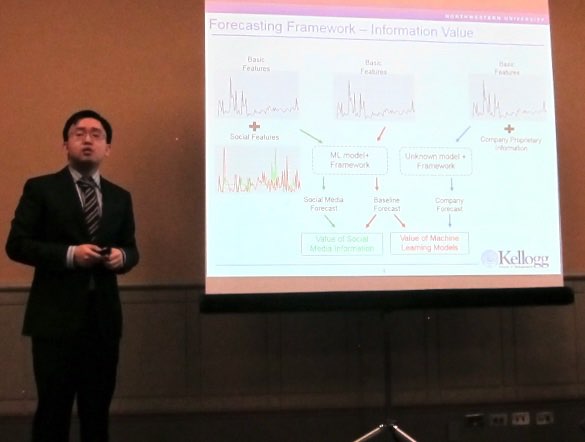
We started out in the session titled “Empirical Research in Services and Retail”. The talk in this session I liked most was by Dennis Zhang (Kellogg School of Management, Northwestern University, see picture below) titled “The Operational Value of Social Media Information”.

Next up was the welcome plenary. The general chair of Tamas Terlaky (Lehigh University, see picture below).


The opening talk was by Margaret L. Brandeau (Stanford University, see picture below) titled “Creating Impact with Operations Research in Health.” She discussed her experiences in using OR to inform and influence decisions in health and provides a blueprint for researchers who wish to find success by taking a similar path.


Next, we attended the “Bridging Business and Analytics” session to check out our US competition in Analytics programs. Mingfei Li (Bentley University, see picture below) presented their survey results. It’s nice to see that in terms of skill set (see right-hand side of her slide) our programs (MScMA and Data Analytics in Business Engineering) include most of them: SQL, R, SAS, Python, ... .

After lunch, we attended Dr. Stephen J. Wright’s (University of Wisconsin-Madison, see picture below) talk. He started out with the more traditional techniques, but then he devoted a lot of attention to the newer algorithms such as Deep Learning (some of his slides are shown below).





During the coffee break, we visited the INFORMS job fair. Lots of famous companies are hiring data scientists at this event. By far the biggest booth was run by Amazon. Others included American Airlines, BNSF Railway, United Airlines, and Uber.



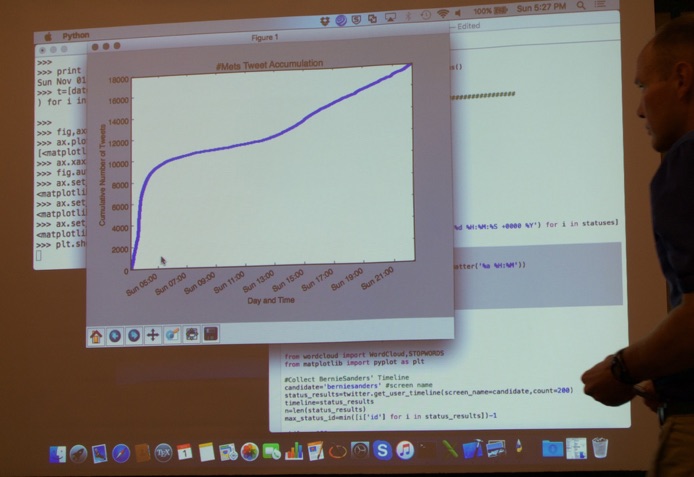
After the break, we attended the tutorial titled “Collecting and Analyzing Twitter Data with Python” by the INFORMS Social Media Analytics Section. Chris Marks (MIT, see picture below) gave a great talk explaining in detail how to collect tweets using Twitter’s APIs, and how to combine this with the wordcloud package and pygmaps.



Next, we attended the Business Meeting of the Data Mining Section. See picture below.

We wrapped up our day by attending the INFORMS opening reception.


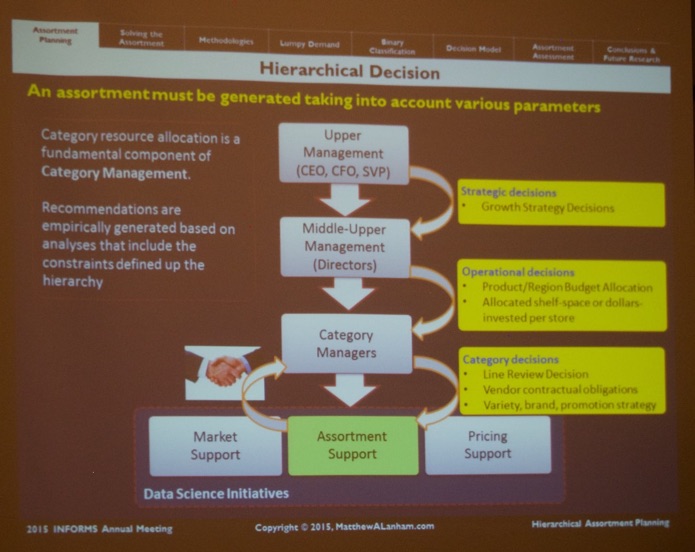
On Monday, Nov. 2nd 2015 at 8 am, I attended the Retail Analytics Session. Matthew Lanham (@MatthewALanham, Doctoral Candidate at Virginia Tech, see picture) was by far the most interesting talk titled “Parameter Estimation Procedures for a Hierarchical Assortment Planning Decision.“ Estimating a consumer’s propensity to purchase a product as well as their substitution behavior are critical parameters to a retailer’s assortment decision. Matthew investigates the methodologies used to understand consumer demand, substitution behavior, and formulate a novel approach that could be used strategically in a hierarchical assortment planning decision model.


Next up was the plenary keynote by Dr. Michael Jordan (UC Berkeley) titled “Computational Thinking, Inferential Thinking and Big Data.”



After the break, Dauwe Vercamer (@DauweVercamer, see picture below) took the stage to present the work for his third essay - part of his PhD - titled “Data-Driven Vehicle Routing with Profits.” In sales teams, making optimal visits is crucial. Customer Profitability models help in identifying top customers, but do not consider the associated visit costs. Vehicle Routing models make efficient schedules, but use naive estimates rather than good forecasts. Our prescriptive analytics approach uses auxiliary data and statistical learning to approximate full-information vehicle routes. The results show this approach improves customer selection in vehicle routes and maximizes profitability.


After lunch, it was time for the “Predicting Customer Behavior using Facebook Data” Session organized and chaired by Prof. Dr. Michel Ballings (@MichelBallings, University of Tennessee at Knoxville, see picture below on the right) as part of the Social Media Analytics Cluster. Matthijs Meire (@MeireMatthijs, PhD candidate at Ghent University, see picture below on the left) kicked off the session with his paper “Using Customers’ Facebook Pages to Improve Lead Qualification in a B2B Acquisition Process.” The purpose of this study is to investigate the added value of Facebook data in B2B customer acquisition. We use a Random Forest prediction model. The results indicate that adding customers’ Facebook page data can indeed improve B2B lead qualification. Our contribution is twofold. First, to the best of our knowledge it is the first to use Facebook data in B2B lead qualification. Second, we quantify the monetary gains of using Facebook data by conducting a real-life lead targeting experiment.


Next, Steven Hoornaert (@HoornaertSteven, PhD candidate at Ghent University, see picture below) presented his talk “Investigating the Drivers of Likes and Comments on Facebook.” The objective of this study is to investigate the added value of user context data in Facebook post popularity prediction models. For this purpose, two Random Forest models were built: one including only post variables (e.g., post type) and another containing both post and user variables (e.g., age). Predictability is improved for likes (x3.7) and comments (x3.6). This study is the first to augment post popularity prediction models with user context data and analyze a large quantity of posts.


Next, Matthias Bogaert (@MattBogaertFEB, PhD candidate at Ghent University, see picture below) presented his talk “Predicting Buyer Behavior using Social Media Data.” The purpose of this study is to explain customer behavior (offline event attendance) based on SM data. In order to substantiate our findings, we used propensity score matching and built a Random Forest model. This study reveals that social media data can predict offline event attendance with high predictive accuracy. Moreover, the results suggest that the number of friends that are attending the focal event and event attendance on Facebook were highly significant.

Finally, Prof. Dr. Michel Ballings (@MichelBallings, University of Tennessee at Knoxville) wrapped up the session with his presentation titled “The Power of Facebook to Predict Customer Acquisition and Defection.” The main purpose of this study is to investigate the value of Facebook data in predicting individual customer behavior. In addition we study the importance of different online engagement variables such as likes, answers to event rsvp’s, and group memberships in predicting acquisition and defection. The results indicate that customer acquisition can be predicted very accurately using Facebook data. In addition, Facebook data significantly improve defection prediction over and above customer data.

Next, I attended the Business Meeting of the INFORMS Analytics Section. In the picture below, the new Section president - Jim Williams (@JimWilliams0001) - takes center stage.





In the picture below, you see the former INFORMS president Anne G. Robinson (@agrobins, Verizon) and Polly Mitchell-Guthrie (@SASAnalytics, SAS).


Next, the 2015 Innovative Applications in Analytics Award (IAAA, sponsored by Caterpillar) was awarded to the Mayo Clinic.


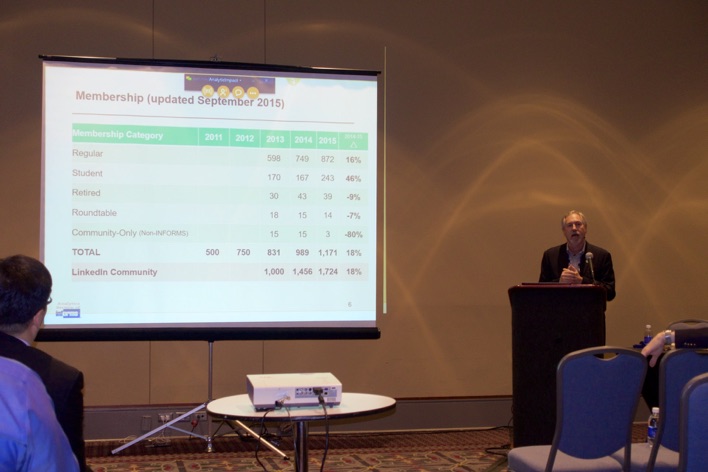
In the picture below, you see Glenn Wegryn (@gwegryn, on the left-hand side) being awarded a certificate of appreciation for chairing the Analytics Section by Jim Williams (@JimWilliams0001, on the right-hand side), who is taking over the presidency. As shown below, membership has increased again by 18%.

Next, we headed to the SAS Event in the Marriott hotel.





On Tuesday, Nov. 3rd, 2015, I started the day with the “Financial Applications of Data Mining and Machine Learning Techniques” Session. Dr. Shijie Deng (Georgia Inst of Tech, see picture below) kicked off the day with his talk titled “Optimal Global Efficient Portfolio with Emerging Markets using
Earning Forecasts”. He applies a multi-factor stock selection model which includes earning forecast to
analyze the performance of the optimal global portfolio using the Markowitz mean-variance framework.





Next, John Guerard (Director of Quantitative Research at McKinley Capital Management, see picture below) took the stage with his talk “Data Mining Corrections Testing.” He concludes that earnings forecasting models and regression-based models emphasizing forecasted earnings acceleration and price momentum models dominate the DMC (i.e., Data Mining Corrections) tests.

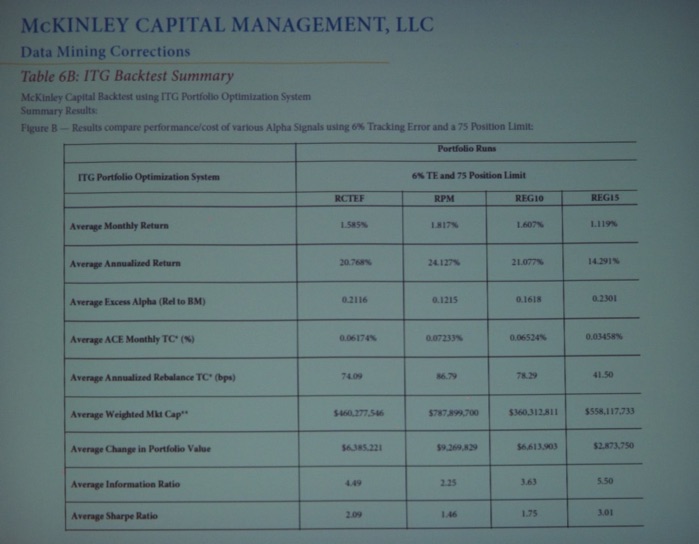
Next, Sundaram Chettiappan (Senior Quantitative Research Analyst at McKinley Capital Management, see picture below) gave his talk “Applications of Machine Learning over Alpha Signals to Improve Stock Selection and Boost Returns.” He shows that machine learning techniques can have statistically significant additions to both raw returns and simulated returns in various equity universes. These excess returns are mostly attributed to improved stock selection as the risk profile doesn’t change significantly in terms of both direct risk measurements (standard deviation based risk models) and exposures to various fundamental factors.




Next, Dr. Alfred Spector gave a plenary talk titled “Optimization, Machine Learning, and their implications in the World of Big Data.”



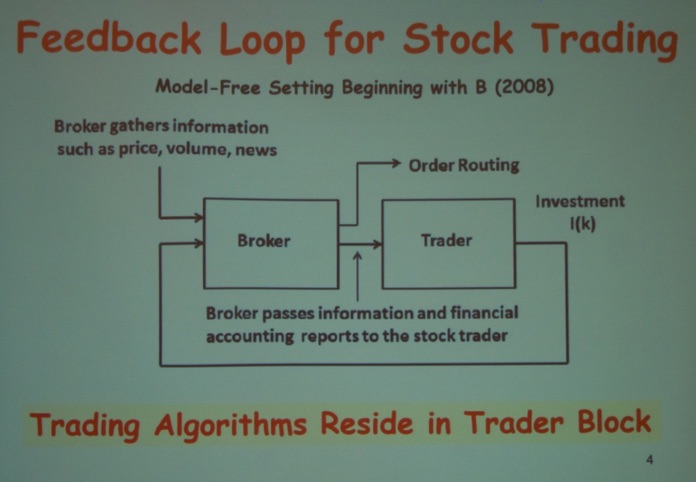
Next, I attended the “Engineering Approaches in Finance” Session. First, Bob (Ross) Barmish (Professor at University of Wisconsin) delivered his very inspiring talk “On Feedback Control-based Stock Trading: Some Back Tests with High-frequency Data.”

Next, Dr. Yuji Yamada (Professor at the University of Tsukuba) gave a talk titled “Construction of Nonlinear Simultaneous Equations Models for Electricity Supply and Demand Functions.”

Next, Dr. James Primbs (Associate Professor at California State University Fullerton) delivered the talk “Trading a Portfolio of Pairs in the Presence of Transaction Costs.”
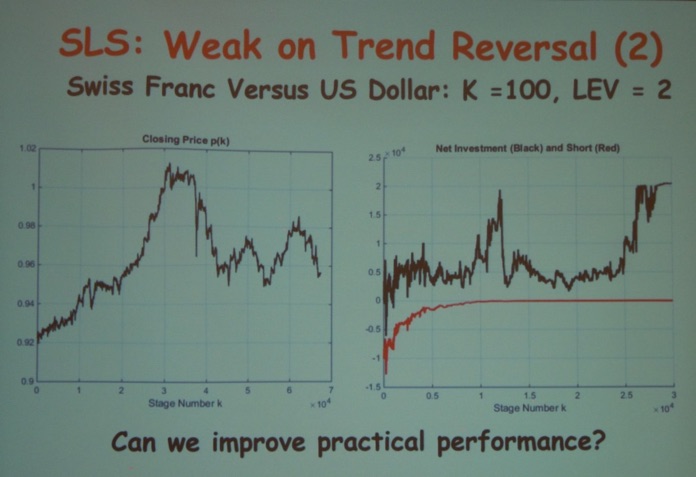


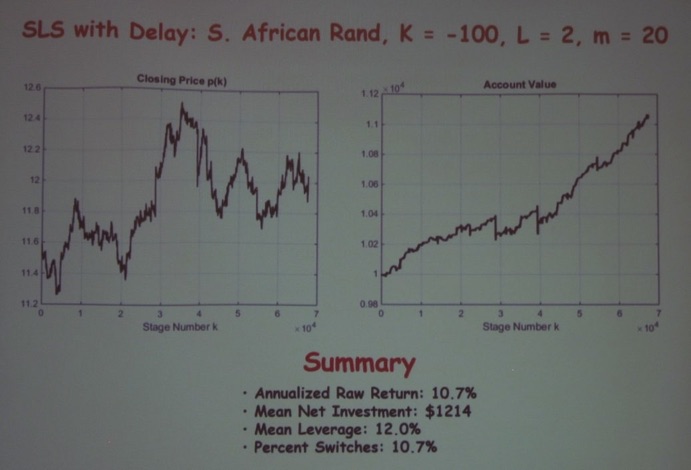
The final talk by the session was by Sean Warnick (Associate Professor at Brigham Young University) titled “Backtesting Simultaneous Long-short and Proportional-integral Investment Schemes.”

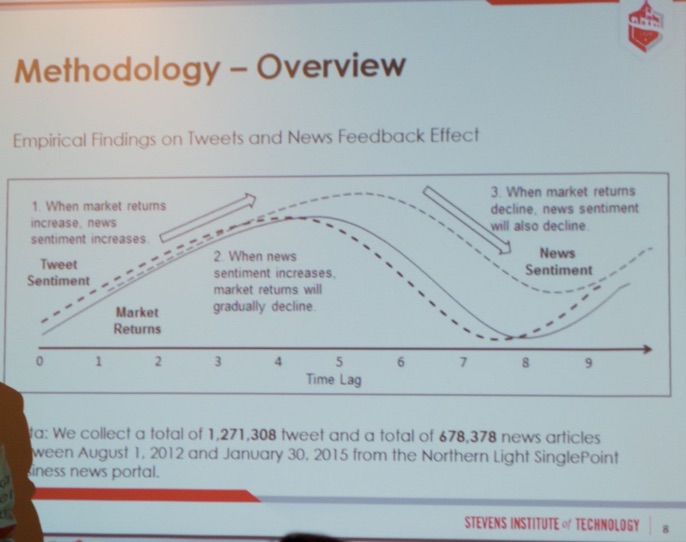
After lunch, I attended Dr. Steve Yang’s (Assistant Professor at the Stevens Institute of Technology) talk titled “Genetic Programming Optimization for a Sentiment Feedback Strength Based Trading Strategy.”


Next, Zhen Liu (Numerix, see picture below) gave a talk titled “Linear Programming Approach to American Option Pricing.”

On Wednesday, we attended the Social Media Analytics Section session titled “Identifying Sentiment Change and Geographic Location in Social Media.” First, Patrick Dudas (Contractor at NPS, see picture below) presented the talk “Better Defining Location and Attribute Data in Twitter by Utilizing Wikipedia Localization Text.”

Next, Les Servi (@lds123, MITRE Corp., see picture below) presented the talk “Non-linear Dynamics of Human Emotions: Analysis of Twitter Data and its Implications.”


After the break, Dr. Patrali Chatterjee (Professor, Montclair State University, see picture below) gave a talk titled “What Products to Feature on Retail Website Landing Pages?”


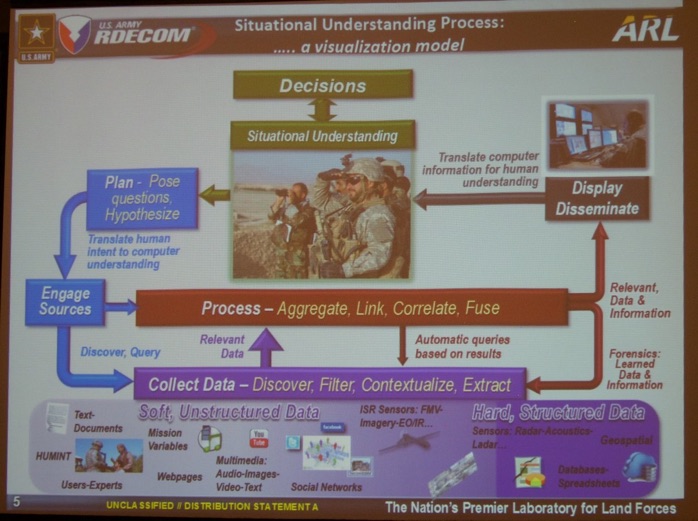
Finally, Michael A. Kolodny (Senior Technology Advisor at the Army Research Laboratory, @RDECOM, see picture below) gave his talk “Situational Understanding: A Military Perspective of Where we Need to Go and the Exploitation of Open Source Data Utilizing “Social Signal Processing for Anomaly Determination.”


After lunch, we continued to attend the Social Media track. The first talk was by Yulia Tyshchuk (@WestPoint_USMA, Researcher, USMA) titled “Modeling Human Behavior in the Context of Social Media During Extreme Events.”



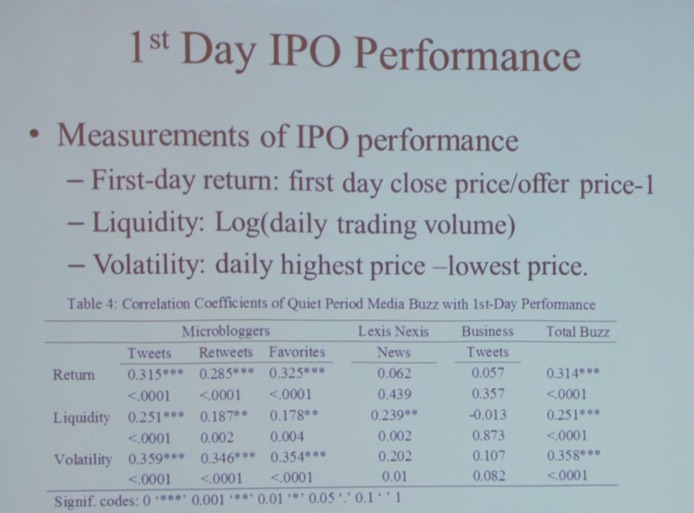
Next, Dr. Julie Zhang (Assistant Professor, University of Massachusetts) gave a talk titled “Social Media Whispers during IPO Quiet Period”.


As the final talk, we attended Dr. Inbal Yahav’s (Bar Ilan University) presentation titled “Simulating Twitter Ego Networks.”

