ASE 2014 Big Data Conference at Stanford University

On May 27, the ASE Big Data conference kicked-off with workshops. The first speaker, Dr. Kalyan Veeralachaneni (Research Scientist at ALFA Group, MIT, see picture below) gave a talk titled “From JSON Logs to Latent Variable Models: Knowledge Mining Massive Open Online Courses (MOOC) Data”. He shared a lot of the details how they compiled good predictors for MOOC outcome variables (see slides below), in this case whether students stop their participation. His most memorable statement was “We care more about getting the variables right than we care about the models themselves”.
Saturday 31 May 2014

In sum, this was a great event. Congrats to the organizers! It brought together a large group of researchers from very diverse areas.




Next, I switched to the Social Computing for Urban Intelligence and Smarter Lives Workshop. Here, Piotr Szczytowski (NEC Labs Europe, see picture below) was giving a talk titled “Geo-fencing based Disaster Management Service”.

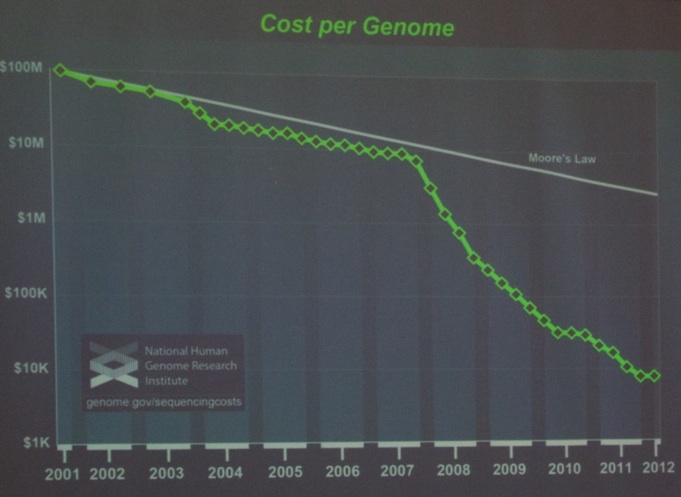
Next, Dr. Srinivas Aluru (Georgia Institute of Technology, see picture below) presented his talk titled “Big Data Challenges in the Biosciences”. The decrease in cost to sequence a complex organism’s DNA (from $100 million down to $1000, see slide below) has enabled many new applications in human health, agricultural biotechnology, ... .


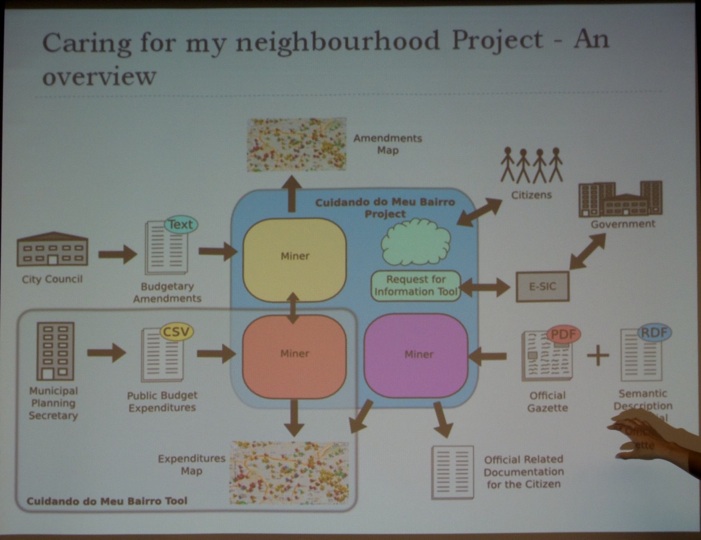
In the same workshop, Prof. Dr. Gisele da Silva Craveiro (University of Sao Paulo, Brazil, see picture below) gave a talk titled “Caring for My Neighborhood: A Platform for Public Oversight”. She starts by highlighting the importance of open data. She illustrates this point by geocoding budget expenditures. This allows her to show the budget data on a map where projects are planned or spent.

Finally, Kelly Shigeno (IBM Research, Brazil, see picture below) presented his talk “Inferring Social Intelligence from Open Communication Interfaces”.
Next, I switched to the International Workshop on Exploiting Big Data in Commerce and Finance. There, I learned about the hikaku project during the talk titled “LOD Metadata Harvester: Enabling Better Decision Making” by Vivian Lee, Aisha Naseer and Terunobu Kume (Fujitsu Labs of Europe Ltd, see picture below). They propose a framework to merge internal data with open data. See http://lod4all.net . Currently, it holds metadata on 461 open datasets.


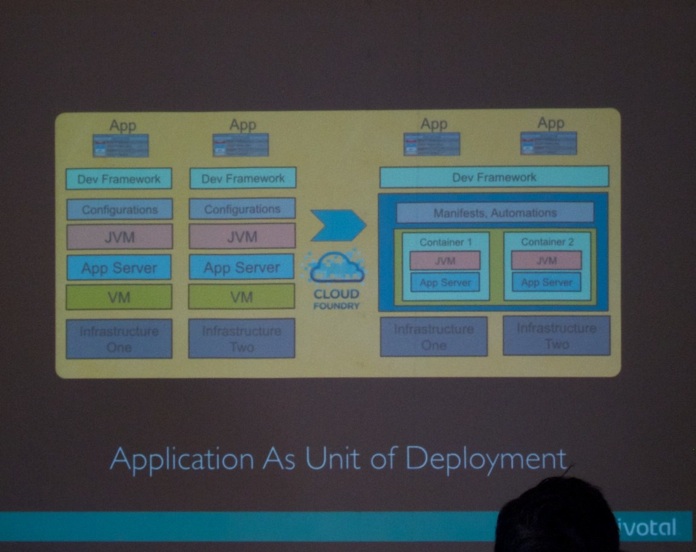
May 28 - Day 2 of the ASE Big Data conference - started off with a plenary session by Dr. Milind Bhandarkar (Chief Scientist at Pivotal Inc., see picture below) on the topic “The Future of Data-Intensive Applications”. He talks about Cloud Foundry.


Next, Dr. Michelle Zhou (Senior Research Manager at IBM Research - Almaden, see picture below) gave a talk titled “System U: Computational Discovery of Personality Traits from Social Media to Deliver Hyper-Personalized Experience”. She talks about individualisation at scale.
Psycholinguistic studies have shown that the words people use reflect their personality
(e.g., derive personality from tweets), labeled System U (by IBM).





Then, Dr. Carl Landwehr (Lead Research Scientist at George Washington University, see picture below) took the stage with the talk titled “A Building Code for Building Code”. He introduces the metaphor of a building code to talk about building better software code.




Next, Gerard Warrens (CEO at Stealth Software, see picture below) delivered the talk “Insight into the World of Cybercrime and Cloud Computing”. Problem of data breaches is high (estimated to be about $114 Billion), but the problem of IP theft ($250 Billion) is way higher.



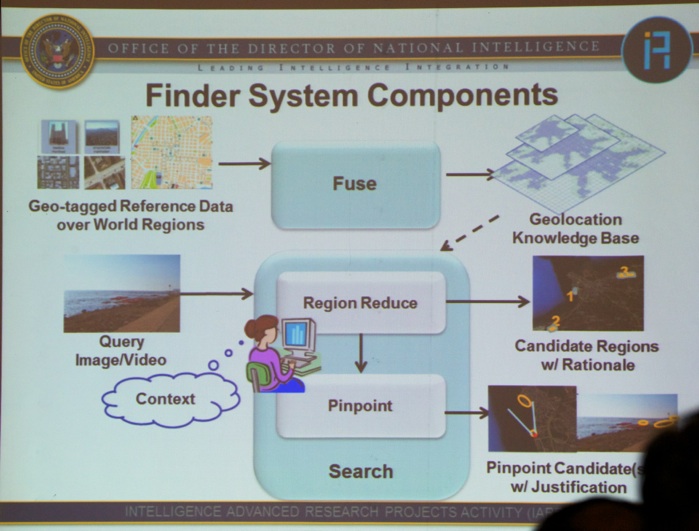
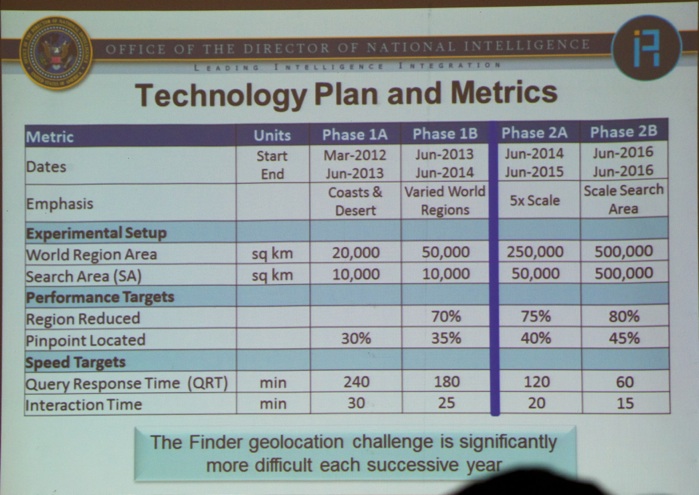
Next, Dr. Jill D. Crisman (Program Manager at IARPA, Office of the Director of National Intelligence, see picture below) took the stage with a talk titled “Big Data in the Finder and Aladdin Video Programs”.


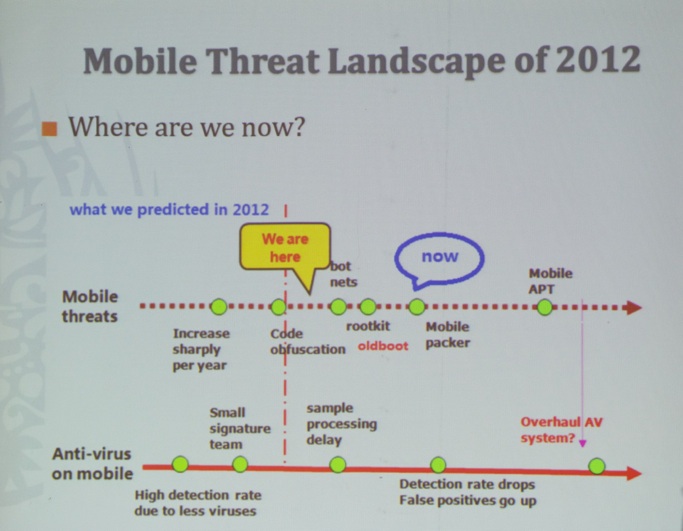
Next, Dr. Wei Yan (CEO VisualThreat Inc., see picture below) took the stage to give a talk titled “Generate Comprehensive Threat Reports and Security Scores for Android Apps”.


Next, Prof. Dr. Stanley C. Ahalt (Director at RENCI) emphasized the shift from a compute-centric world to data-centric research.

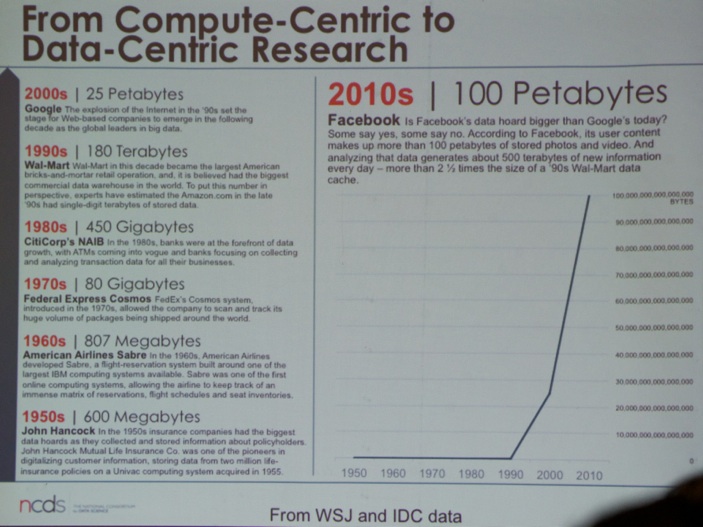

The last speaker for the morning session was by Dr. Vinod Khosla (Partner at Khosla Ventures, see picture below) on Big Data in Healthcare.


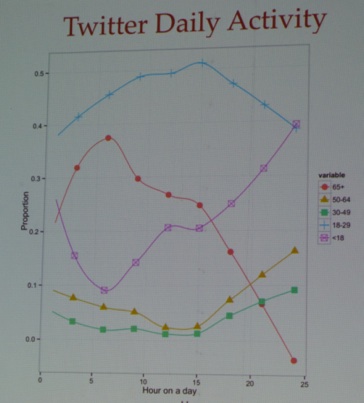
After lunch, I decided to attend the social media track. Shana Dacres (QML, see picture below) et al. talked about advertising strategies on Twitter, more specifically, promoted influences within Twitter: 1. Promoted Tweets, 2. Promoted Trends, 3. Promoted Accounts. See results below:
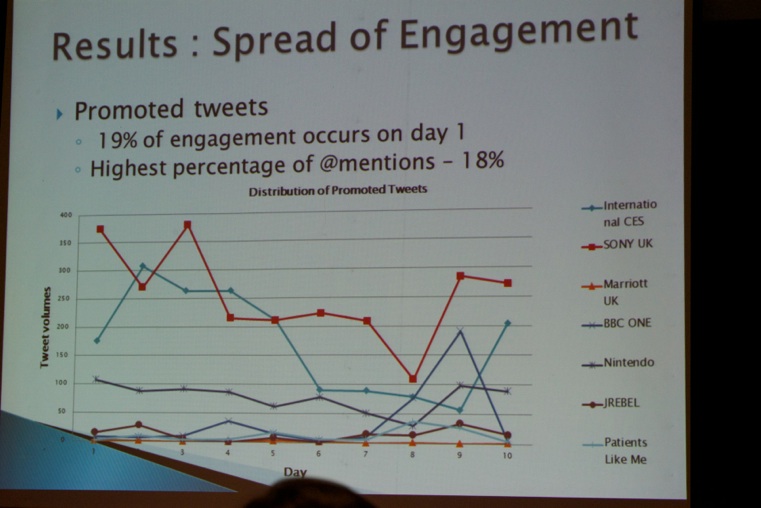
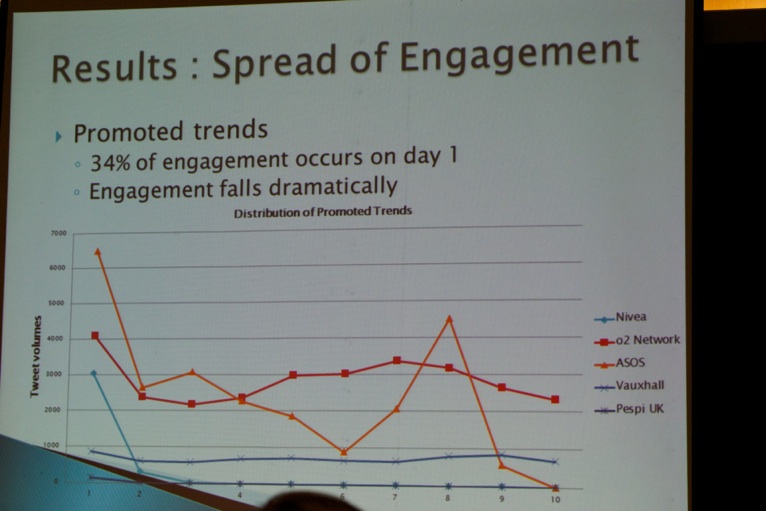

Next, Hashim Sharif (LUMS), Ahmed Abbasi (University of Virgnia), Fareed Zaffar (LUMS), and David Zimbra (Santa Clara University) presented their paper titled “Detecting Adverse Drug Reactions using a Sentiment Classification Framework”.

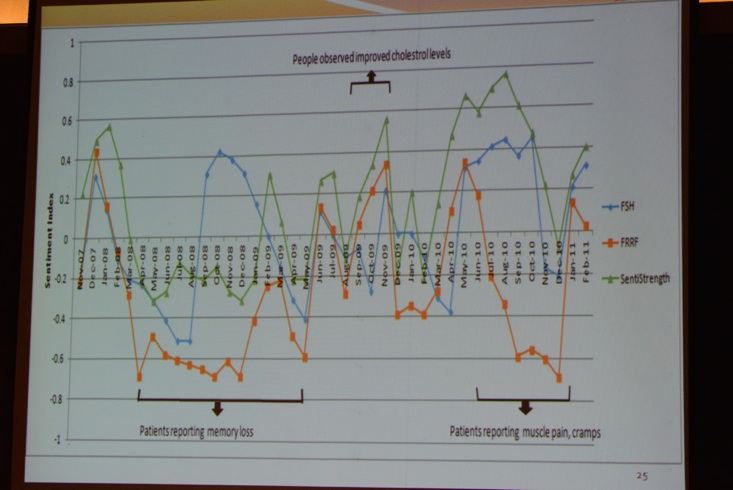

Next, Byungkyu Kang (UC Santa Barbara) and John O'Donovan (UC Santa Barbara, see picture below) presented their talk “Competence Modeling in Twitter: Mapping Theory to Practice”.


Next, Huseyin Oktay (UMass, see picture below) presented the paper “Demographic breakdown of Twitter users: An analysis based on names”.

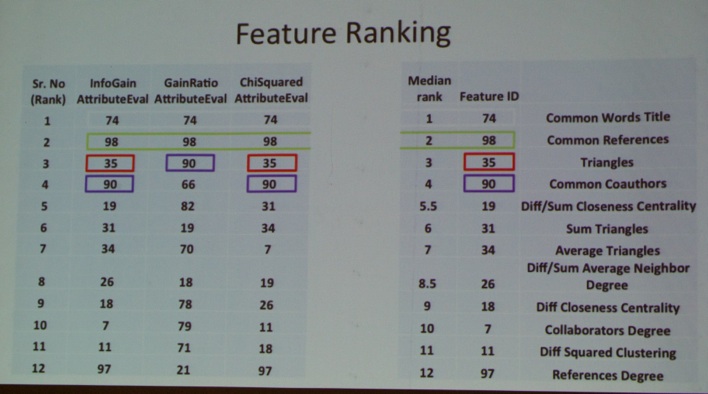
Finally, Irfan Bukhari (National University of Sciences and Technology, Islamabad) et al. wrapped up the social media session with their talk “Predicting New Collaborations in Academic Citation Networks of IEEE and ACM Conferences”.


Next, it was time for the first poster session of the conference. It was also time for yours truly to become active (@dirkvandenpoel, see picture below) with “Scalable Real-Time Big Data Internet-of-Things Platform for Connected Cars” (co-author: Michiel Van Herwegen - Ghent University). This is joint research with @Technicolor’s Virdata team.


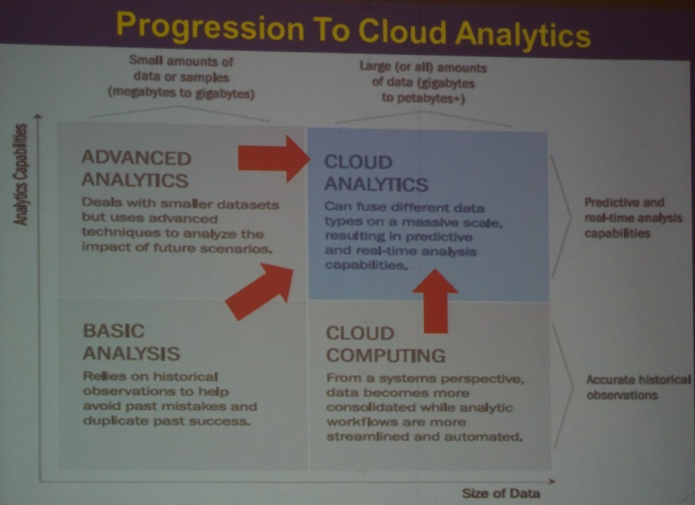
On May 29, Dr. Kai Hwang (Professor at University of Southern California, see picture below) kicked off the event with a talk titled “Enabling Cloud Analytics for Big-Data Security and Intelligence”.

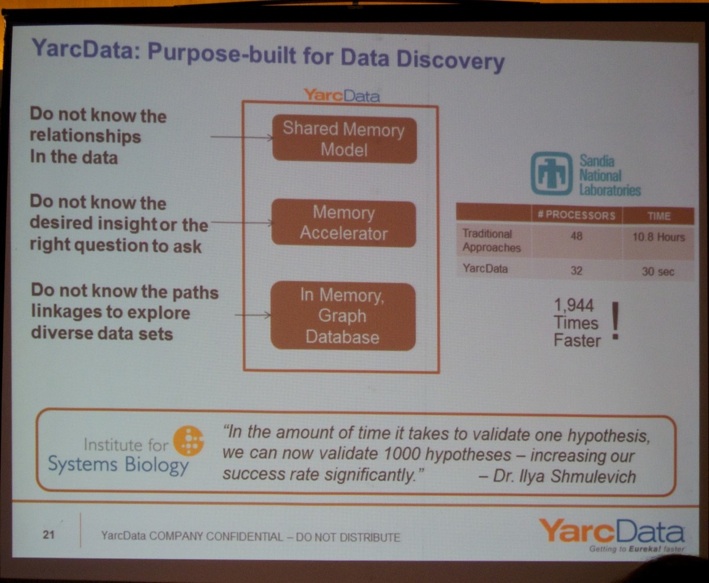
Next, Arvind Parthasarathi (President at YarcData, Inc., see picture below) gave a talk “Delivering on the Promise of Big Data”. He emphasizes that the “Big Data” revolution puts a lot of pressure on IT budgets, which on average only grow by 5% per year. Still organizations have to cope with a 40% data/systems growth per year. Next, he presented YarcData’s purpose-built system for data discovery. They offer a combination of hard- and software.

Then, Rebecca D. Costa (see picture below) - evolutionary biologist - took the stage. She argues that we adapt very slowly to change. We enter a high failure-rate environment (the number of wrong options is growing much faster than the number of right options). See the slide below on how to succeed in such an environment.



Next, we had the panel (see picture below) titled “The Cautionary Side of Big Data” with Moderator: American Sociobiologist and Author, Rebecca D. Costa; Panelists: Steve Beier (IBM Big Data Program Director), Guy Kawasaki (author, entrepreneur and business advisor) and Forrest Melton (Senior Research Scientist NASA Ames Research Center).


After the coffee break, Dr. Mario Inchiosa (Revolution Analytics, Inc., see picture below) discussed “Scaling R to Big Data Science”.


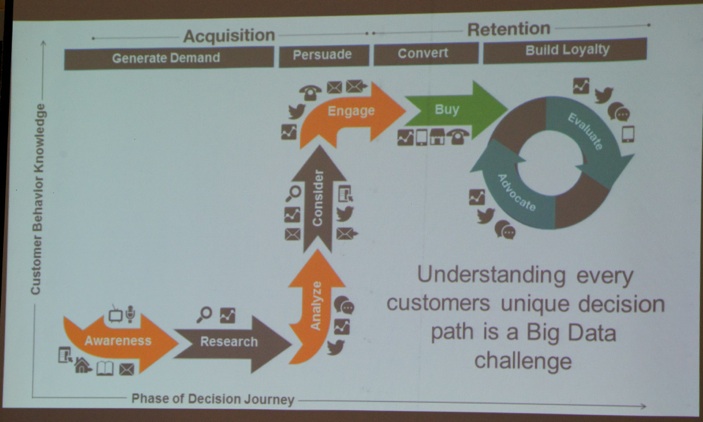
Next, Matt Hertig (@MattHertig, Co-Founder Alight Analytics, see picture below) gave a talk titled “Big Data and The Customer Decision Journey”.


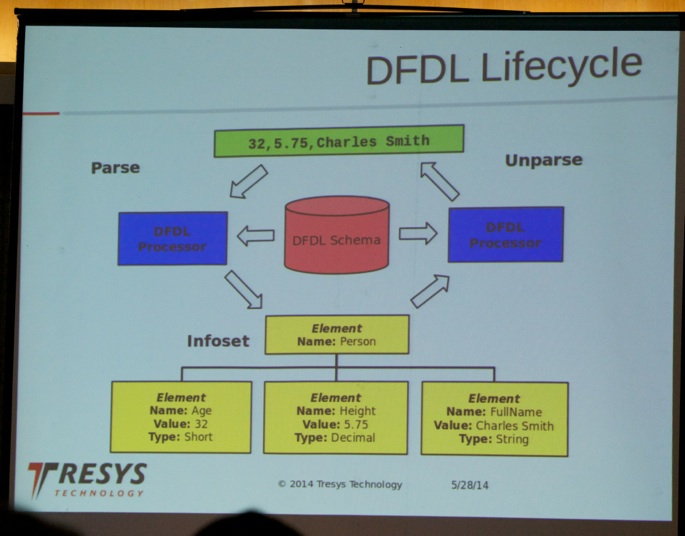
Next, Stephen Lawrence (Software Engineer at Tresys Technology, Inc., see picture below) presented the talk “Simplified Data Parsing and Ingestion with DFDL”.


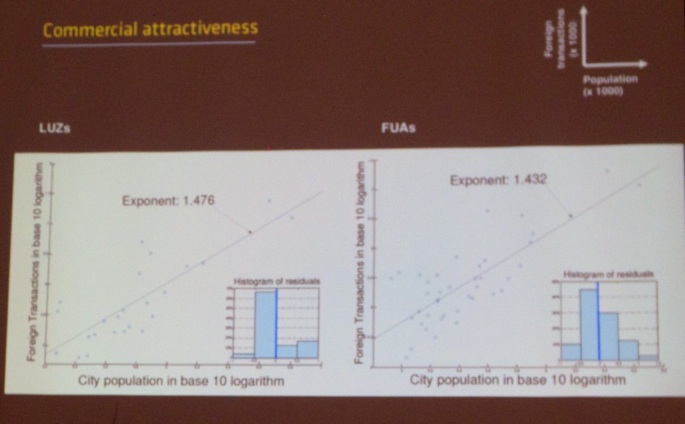
After lunch, Stanislav Sobolevsky (SENSEable city lab, MIT, see picture below) et al. presented their talk titled “Mining Urban Performance: Scale-Independent Classification of Cities Based on Individual Economic Transactions”.

Next, Angana Chakraborty (Indian Statistical Institute), Sanghamitra Bandyopadhyay (Indian Statistical Institute) presented their talk “A Layered Locality Sensitive Hashing based Sequence Similarity Search Algorithm for Web Sessions”.





Then, I decided to switch to the social media track. Hence, I attended the talk of the paper titled “Will this Celebrity Tweet Go Viral? An Investigation of Retweets” (Lisa Gandy, Central Michigan University; Libby Hemphill, Illinois Institute of Technology).



Next, the paper titled “Analysis and Modeling of Lowest Unique Bid Auctions” (Tanmoy Chakraborty, Indian Institute of Technology - Kharagpur, India; Vihar Tammana, Microsoft Corporation, Redmond, USA; Niloy Ganguly, Indian Institute of Technology - Kharagpur, India; Animesh Mukherjee, Dept. of CSE, IIT Kharagpur).

Next, the paper titled “Classifying News Authors Based on their Authoritativeness” was presented (Riham Mansour, Microsoft Research; Tamer Deif, Microsoft research; Antoine Morcos, Microsoft Research)



Finally, it was time for another set of poster presentations.

On May 30th, Prof. Dr. S. Felix Wu (University of California-Davis, see picture below) gave a talk titled “On Content, Discussions, Opinions, and Deliberative Participation over Social Media Systems”.


Next, Dr. Bhavani Thuraisingham (The University of Texas at Dallas, see picture below) presented her talk “Cloud-Centric Assured Information Sharing”.

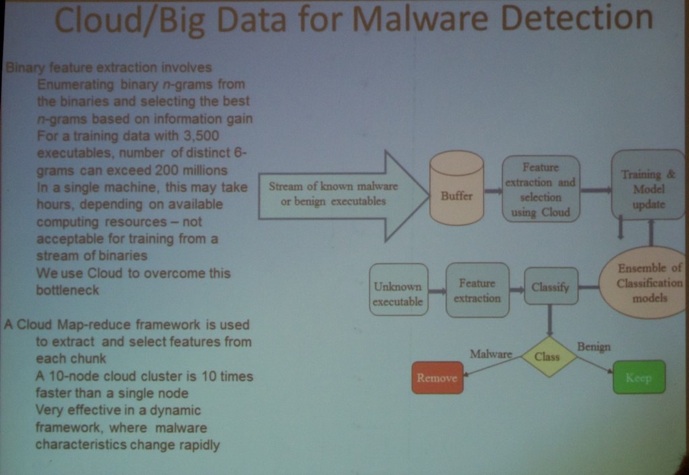
Next, Dr. Ketty Gann (Northrop Grumman Information Systems, see picture below) gave a talk titled “Twitter Analytics for Insider Trading Fraud Detection System”.



Next, Dr. Damir Herman (Senior Data Scientist, see picture below) took the stage with his talk “Augmenting Text Analysis: Text Insights and Social Media”.


Next, I attended the social media workshop. I attended the talk titled “Political Social Networks Reveal Strong Party Loyalty in Brazil and Weak Regionalism” by Marcos Oliveira (Florida Institute of Technology), Carmelo Bastos-Filho (University of Pernambuco), Ronaldo Menezes (Florida Institute of Technology).



Next, I attended the paper by Nasser Alsaedi (Cardiff University), Pete Burnap (Cardiff University) titled “A Combined Classification-Clustering Framework for Identifying Disruptive Events”.



Next, the presentation titled “Data Matters: Reflection on User Defined Social Prioritization” by Juwel Rana (Telenor Research), Kåre Synnes (Luleå University of Technology), Johan Kristiansson (Luleå University of Technology) was held.


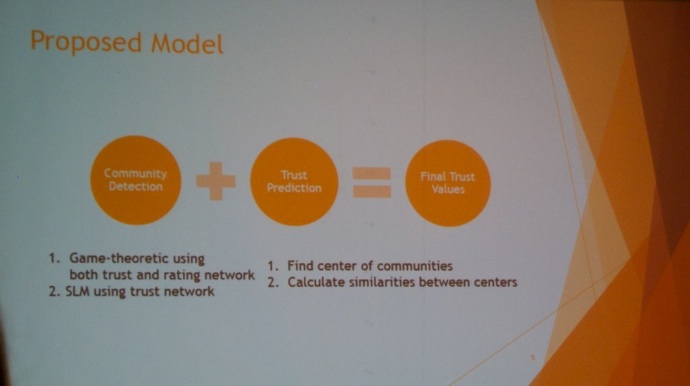
Next, I attended the talk titled “Leveraging Community Detection for Accurate Trust Prediction” by
Ghazaleh Beigi (Sharif University of Technology), Mahdi Jalili (Sharif University of Technology),
Hamidreza Alvari (University of Central Florida), Gita Sukthankar (Department of EECS, University of Central Florida).


Next, the paper titled “A Visibility-based Model for Link Prediction in Social Media” was presented by
Linhong Zhu (Information Sciences Institute), Kristina Lerman (Information Sciences Institute).



Next, the third poster session was held. Below, two of the participants are shown.


On May 31st - the last day of the conference - Dr. Michael Mahoney (ICSI and UC Berkeley, see picture below) kicked off the event with a talk titled “Randomized matrix algorithms and large-scale scientific data analysis”.





Next, the paper titled “Discovering Community Structure in Dynamic Social Networks using the Correlation Density Rank” was presented by Zeynab Bahrami Bidoni (Clark Atlanta University), Roy George (Clark Atlanta University).


Next, I attended the paper titled “Using Interactions in the Quantification of Media Bias” by Diego Pacheco (Florida Institute of Technology), Dillon Rose (Florida Institute of Technology), Fernando Lima-Neto (University of Pernambuco), Ronaldo Menezes (Florida Institute of Technolog)


Next, the paper titled “Information Relaxation is Ultradiffusive” by Rumi Ghosh (HP), Bernardo Huberman (HP) was presented.



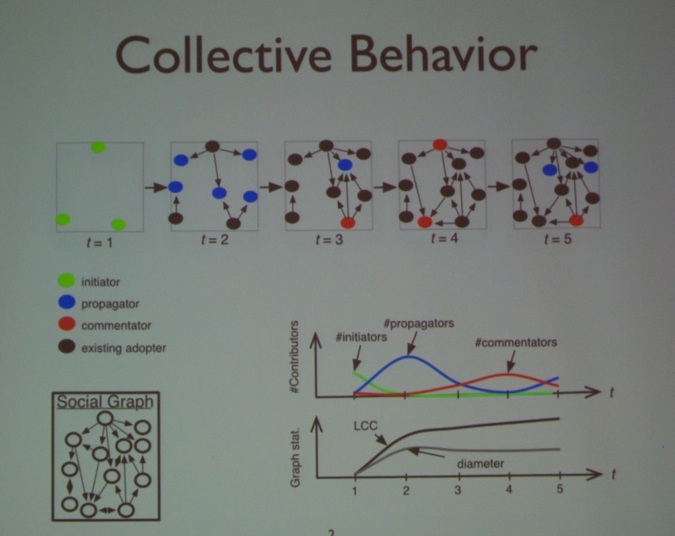
After the coffee break, I attended the presentation titled “ASH: Scalable Mining of Collective Behaviors in Social Media using Riemannian Geometry” by Huan-Kai Peng (Carnegie Mellon University, see picture below), Radu Marculescu (Carnegie Mellon University).


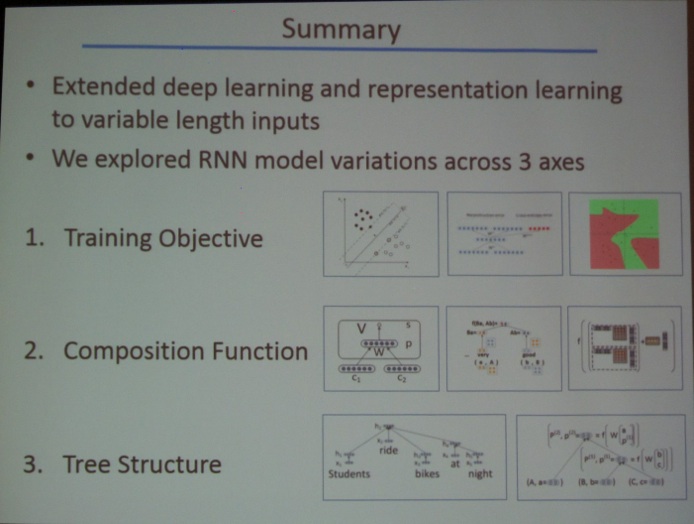
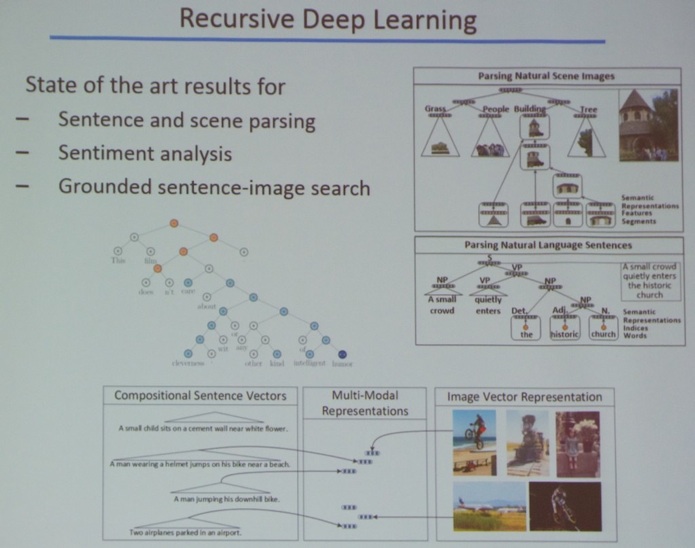
Next, I attended Dr. Richard Socher’s (Department of Computer Science at Stanford University, see picture below) talk titled “Deep Learning for Natural Language Processing”.

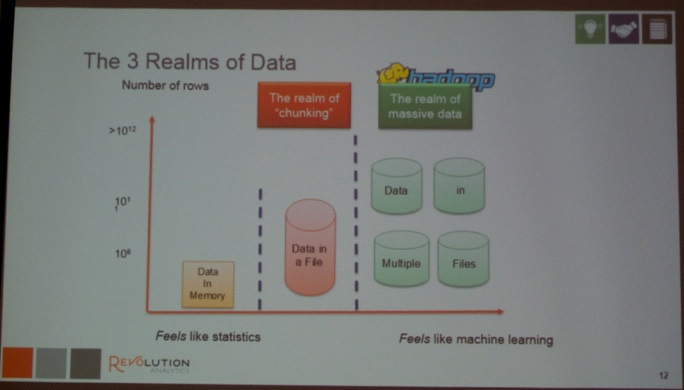
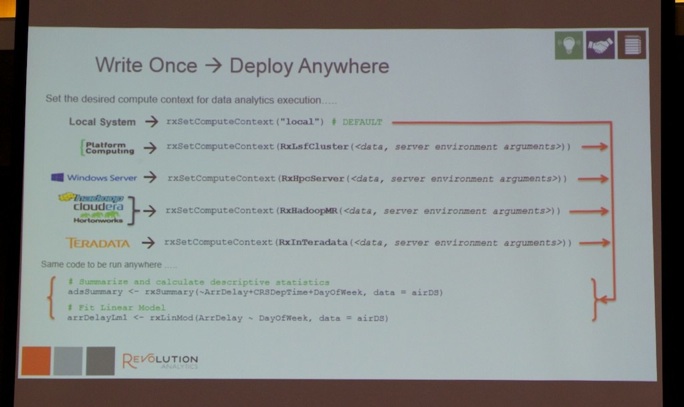
After lunch, Joseph Rickert (see picture below) and Dr. Mario Inchiosa of Revolution Analytics, Inc. delivered a very interesting tutorial, highlighting the big-data extensions provided by Revolution Analytics.



Finally, Michael Schoffner (RENCI) delivered a talk titled “Toward Integrated Security in Cloud Based Data and Compute Infrastructures”.