ACM KDD 2013 in Chicago, IL

The KDD conference #kdd2013 in Chicago from August 10-14 is one of the prime events in the data mining, big data space. This is illustrated by this year's record-breaking attendance of 1200+ data scientists (both researchers and practitioners) from academia, industry, and government. It's organized by ACMs SIGKDD (Knowledge Discovery and Data Mining).
This is a personal summary of the event, based on my choices of the sessions. All pictures are my own (@dirkvandenpoel). At any time, there were many sessions in parallel. Let's have an in-depth look at the event in chronological order.
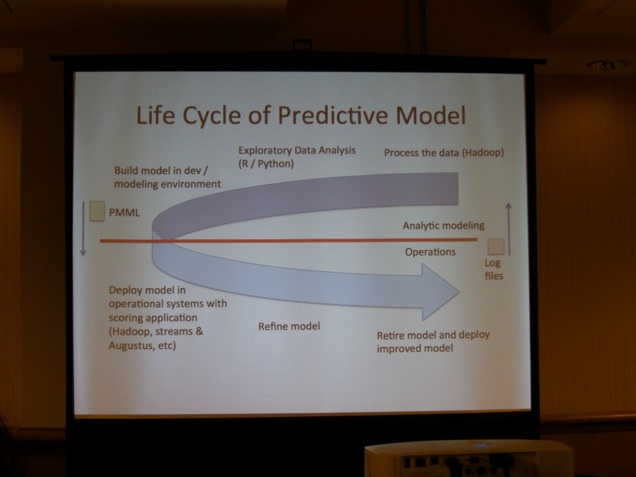
On Saturday, KDD’s Big Data Camp kicked off the event. About 150 data scientists joined this pre-conference bootcamp. Prof. Dr. Robert Grossman (University of Chicago, Open Data Group, see picture below) kicked off the event with an introduction. He emphasizes that both R and Python are gaining traction. R dominates the modelling space (top half of the figure below), Python dominates the IT deployment space (mainly because of R’s restrictive GPL license). He also highlighted OSDC’s public datasets initiative. He also discussed the life cycle of a predictive model.
Thursday 15 August 2013

Next, Jeffrey Ryan (Lemnica Corporation, see picture below) gave an introduction to high-performance R for large datasets. His main expertise is in the analysis of financial Time Series in R. He emphasizes the performance penalty of very large data.frames. He highlights the use of "Environments in R" (they act like lists). Moreover, he promotes the use of data.table as a fast, efficient alternative to data.frames. He is the author of several R packages (xts for comprehensive time series analysis, mmap for a useful view on a file). He is co-organizer of the R/Finance event.

Dean Wampler (@deanwampler, Concurrent Thought, see picture below, click here for his slides) was up next about NoSQL databases. He started out by saying that SQL still remains great for ACID transactions (e.g. for updating a bank account you would prefer a relational database). Then, he went about combined projects such as Hive: NewSQL databases combine ACID transactions and the relational model with NoSQL scaling techniques - he is the co-author of the “Programming Hive” book). He discussed the following categories of NoSQL databases: Column-Oriented stores (e.g. Cassandra, HBase, Big Table), Document-Oriented stores (e.g. MongoDB, CouchBase), Key-Value (Tuple) stores (e.g. Amazon SimpleDB, MemcacheDB), eventually-consistent Key-Value stores, and graph stores (e.g. Neo4J, Titan) as well as some interesting new approaches (such as Datomic: without destructive updates, so all previous history is retained and usable).

After lunch, Q Ethan McCallum (@qethanm) talked about R & Hadoop: Getting R to dance with the elephant. He is co-author of the "Parallel R" book. He briefly discussed Segue, RHIPE, Rhadoop (rmr), R+Hadoop (as approaches to do Big Data with R). This was followed by a joint presentation by Collin Bennett and Jim Pivarski (Open Data Group, see picture below). They gave a talk titled “Building and Deploying Predictive Models Using Python, Augustus and PMML”. They also illustrated the use of Augustus with lots of demos. Great content!

To wrap up the day (and also the Big Data Camp), Prof. Dr. Andrew Johnson (University of Illinois at Chicago, see picture below) talked about data visualization in a Big Data era. He gave a lot of examples of the good, the bad and the ugly...

On Sunday, I first attended a talk by Prof. Dr. Hong Cheng (Chinese University of Hong Kong, see picture to the right), titled “Processing Reachability Queries with Realistic Constraints on Massive Networks”.
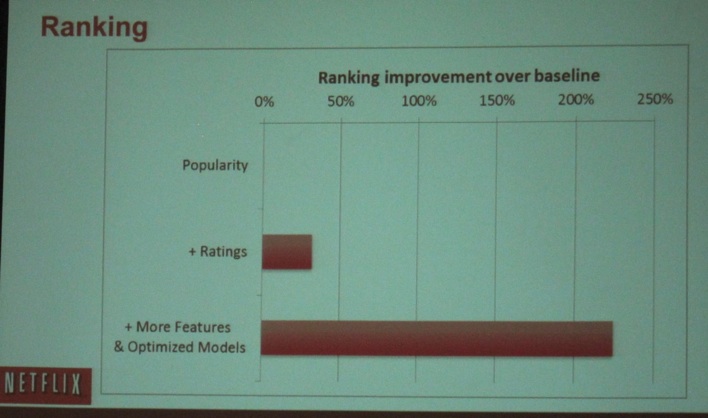
Next up was one of the best talks I heard at KDD this year by Xavier Amatriain (@xamat, Director of Personalization at Netflix, see picture below). His presentation was packed with useful content about personalized movie recommendations. He also confirmed that the "Top 2 algorithms (of the Netflix prize) are still in production". He also mentioned that "Popularity is a tough benchmark to beat in personalization”. Still, they found some improvements (see picture below by using more data (ratings) and better models).




Sunday afternoon, I decided to attend the PMML (Predictive Model Markup Language) workshop. Dr. Alex Guazzelli (@DrAlexGuazzelli, @Zementis, see picture below) presented the pmmlTransformations #rstats package.

Next, Svetlana Levitan (SPSS division at IBM, see picture below) talked about PMML in Simulation. She has been involved with defining the PMML standard right from the start.
Benjamin De Boe (InterSystems, see picture below) presented the talk “Extending the PMML Text Model for Text Categorization”.
Collin Bennett (Open Data Group, see picture below) presented the talk: “Augustus 0.6: Design and Implementation of a Hot-Swappable PMML Scoring Engine “.

Next, Shalini Raghavan (FICO, see picture below) presented her talk titled “Application of PMML to Operationalize Thousands of Predictive Models for Retail “.
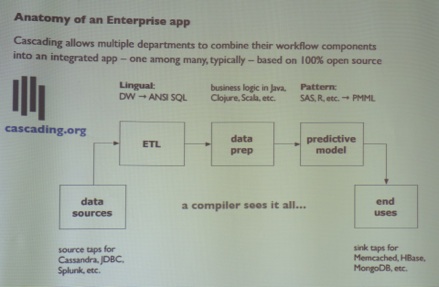
Paco Nathan (@pacoid, Concurrent Inc.) presented the paper “Pattern: PMML for Cascading and Hadoop” (click here for slides). He is the author of the book "Enterprise Data Workflows with Cascading" (O'Reilly Publishing). See http://www.cascading.org for more details.
Then, Dr. Alex Guazzelli took the stage again to present his talk “Extending the Naive Bayes Model Element in PMML: Adding Support for Continuous Input Variables”. Next, Prof. Dr. Michael R. Berthold (KNIME, Universität Konstanz, see picture below) took the stage to talk about Ensembles and PMML in KNIME. The KNIME tool offers an amazingly powerful data analytics engine with a very intuitive interface, combined with nice R interoperability, and great PMML support.
Finally, Michael Zeller (@michaelzeller, CEO @Zementis, see picture below) wrapped up this very interesting pmml workshop. It is clear that a lot has been achieved already. Thanks to Zementis employees and Walt Wells (Operations Manager at Open Cloud Consortium/Data Mining Group) for putting together a very interesting pmml workshop.
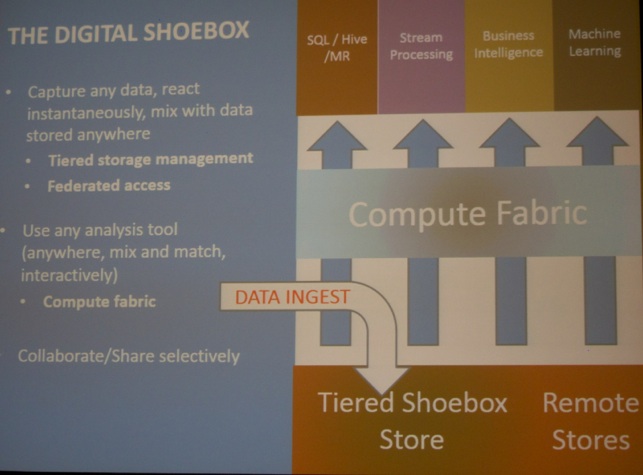
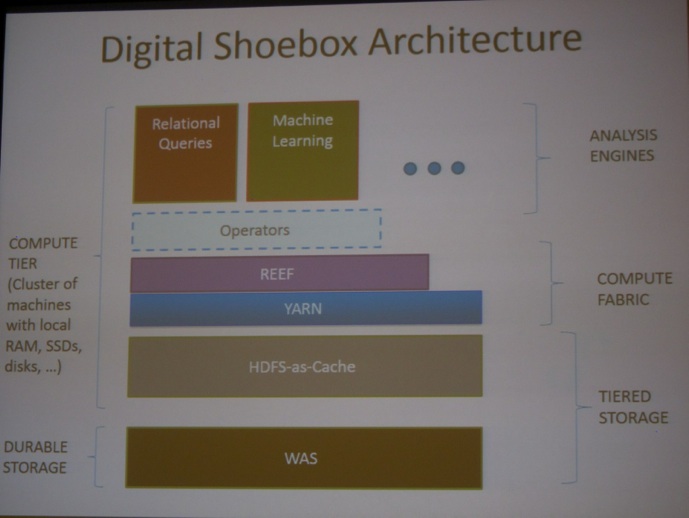
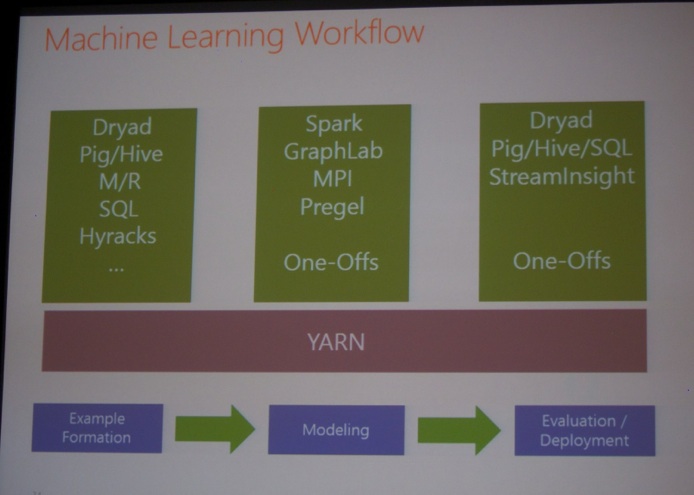
Monday morning started with a keynote by Raghu Ramakrishnan (Microsoft): “Scale-out beyond MapReduce”. He started by explaining how connected devices will dominate our home of the future (Microsoft is planning a HomeOS). Then, he discussed the Machine Learning Workflow in more detail.











In the evening, the two general co-chairs of the KDD 2013 officially opened the event: Robert L. Grossman (Univ. of Chicago and Open Data Group) and Ramasamy Uthurusamy (General Motors Ret.)






Dr. Gabor Melli receiving the 2013 Service Award.
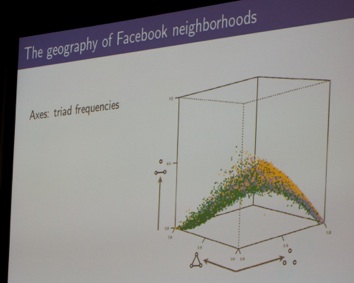
Finally, Prof. Dr. Jon Kleinberg (Cornell University, this year’s SIGKDD Innovation Awardee, see picture to the right) held his lecture titled “Everyday Life in a Data-Rich World”. He highlighted the fact that some network topographies are unlikely because of how people behave (see picture below).

They also presented a data/text mining analysis on the conference content (papers). The KDnuggets website presents this detailed analysis. Next, the (best papers) award ceremony was held, and the KDD 2013 Cup winners were announced. See some pictures below (for more details on the topics, scroll down to the end of this blog post for the best paper session):


Raghu Ramakrishnan announced that Microsoft will open source a big data framework called REEF (Retainable Evaluator Execution Framework). Even the popular tech press (GIGAOM) picked up the announcement: click here.

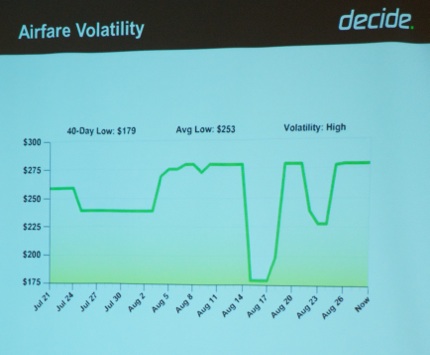
Next, I attended Prof. Dr. Oren Etzioni (University of Washington, @Etzioni, see picture below)’s presentation titled “To Buy or Not to Buy—That is the Question”. He discussed two startups about using big data to help consumers make better purchasing decisions. Farecast (now part of bing travel) tries to predict whether airfares will rise within the next two weeks. See an illustration below of typical airfare price volatility.
After selling Farecast to Microsoft, he went on to found another startup: decide.com (similar concept, but not limited to one product category). This was a great session where he shared many lessons... (see picture below)

After lunch, Prof. Dr. Andrew Ng (@AndrewYNg, Stanford & Coursera.org) held his keynote talk about MOOCs via Goto Meeting. Currently, Coursera courses are modeled after traditional university courses in fixed-size sessions identical for all participant, but MOOCs offer the possibility to truly personalize learning paths by breaking 50-minute sessions into 10-11 minute chunks, and deciding whether a particular student needs to view the different smaller video pieces.

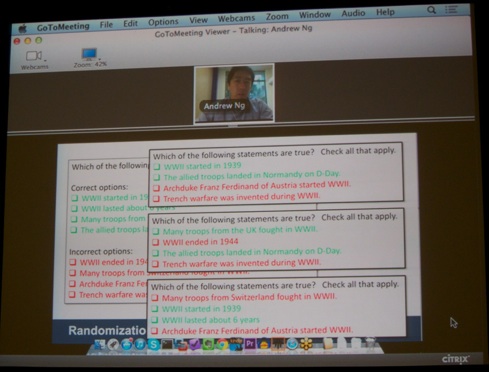
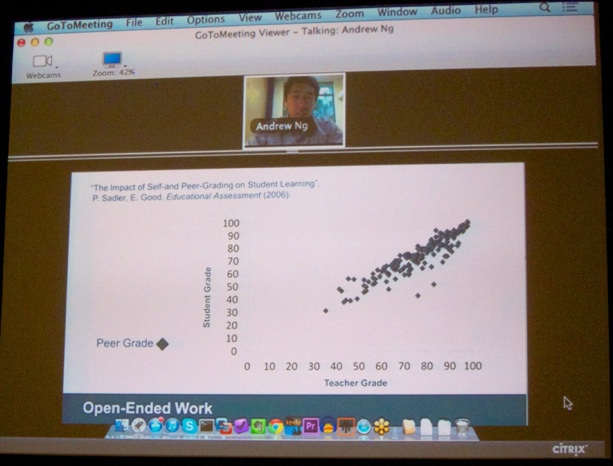
Further, he discussed randomized multiple choice testing (drawing from a larger pool of questions and answers so that even the same student can retest his/her understanding of the material, see picture below). Moreover, in MOOCs grading of 100,000ths of open-ended works is not feasible. There’s evidence that peer-grading or even self-grading may be a feasible strategy.

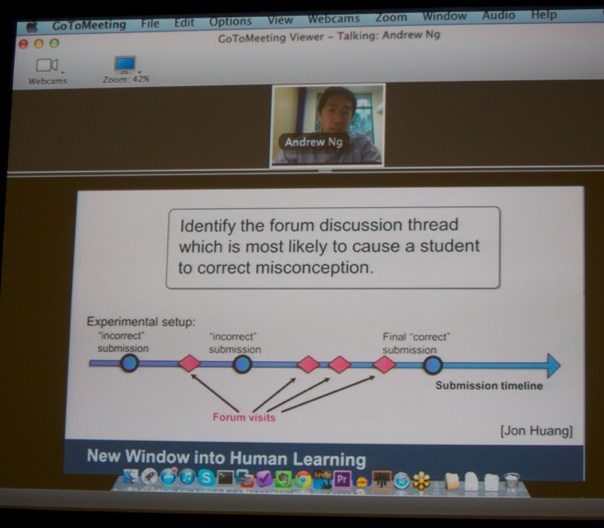
He went on to say that these MOOCs generate so much (pedagogical) data, which can be analyzed to improve the learning experience. He gave the example (shown below) of being able to identify specific forum posts that correct misconceptions best.
Next, I attended Jeremy Howard (@JeremyPHoward, CEO of @Kaggle, see picture on the right)’s session titled “The Business Impact of Deep Learning”. He shared his rich experience from organizing so many predictive analytics competitions. These included: Most kaggle competitions have been won by either Ensembles of Decision Trees or Deep Learning; Most winning techniques share these properties: avoid overfitting + ability to approximate any function; Deep learning power comes from adding & training intermediate layers of neural networks.
Next, Ari Gesher (@alephbass, Palantir, see picture below) gave a nice talk on “Adaptive Adversaries: Building Systems to Fight Fraud and Cyber Intruders”. His many examples (e.g. on how to detect credit card bust-out) made this talk particularly interesting.

During the many breaks, KDD attendees could visit the exhibit hall. These included the usual ‘suspects’ such as Yahoo Research, Microsoft Research, Google, Facebook, ... but also unexpected ones such as Bosch.

The organizers also had a place to recharge laptops and cell phones... nice...





Tuesday morning started with a keynote talk by Prof. Dr. Stephen Wright (see picture below) titled “Optimization in Learning and Data Analysis”. His slide deck is available from his website.



I particularly liked that Prof. Dr. Stephen Wright discussed parallel variants of well-known optimization methods.



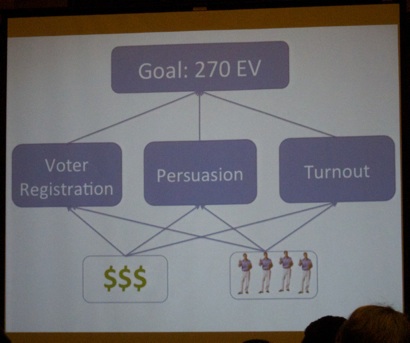
Next, Prof. Dr. Rayid Ghani, (@rayidghani, University of Chicago / Edgeflip, see picture below) talks presidential elections "Using predictive analytics to win elections" (official title: Targeting and Influencing at Scale: From Presidential Elections to Social Good). Again, this industry practice session was very well attended.

Prof. Dr. Rayid Ghani explained they built predictive models to assess voter turnout (at the individual voter level), voter persuasion, and voter registration. Many alternative communication channels were used.
Next, Milind Bhandarkar (@techmilind, Pivotal, see picture below) presented the talk titled “Hadoop: A View from the Trenches” (in the picture you also see Gregory Piatetsky, @kdnuggets, who chaired the session). He started off by giving a brief history of how Hadoop came about. He predicts convergence of #bigdata Hadoop + #hpc + databases at #kdd2013


After lunch, a very interesting panel was held: “A Data Scientist’s Guide to Making Money from Start-ups”. The participants to the panel are shown in the picture below (from left to right): Panelists: Usama Fayyad (@usamaf, Oasis 500, ChoozOn), Oren Etzioni (U. Washington), Geoff Webb (Monash University), Foster Provost (@FakeFoster, NYU), Ron Bekkerman, and Claudia Perlich (@claudia_perlich, M6D). Here are some quotes during the panel discussion:
Oren @Etzioni: The only risk is not doing a start-up, not taking a chance. Start-up is not a risk, it is adventure.
@usamaf talked about lessons learned for startups: A startup gives you the potential for unlimited upside! But "nothing goes as planned" and he noticed that in every single one of his startups, he made the same mistakes again. Moreover, he emphasized the importance of the team (which is even more important than the original idea).
Ron Belkerman: A tech co-founder needs a biz co-founder; VCs are only interested in huge returns (not in moderate exits)
They also talked for while about the issue whether earning a PhD is useful (in a startup career).
The popular press (GIGAOM) also published a summary of this nice panel discussion.



Later in the afternoon, Gregory Piatetsky chaired another panel discussion titled: “Death of the expert? The rise of algorithms and decline of domain experts”. In the picture below you see (from left to right): Gregory Piatetsky (@kdnuggets), Robert Munro (@WWRob, Idibon), Claudia Perlich (@claudia_perlich, M6D), Chris Neumann (@ckneumann, DataHero), John Akred (@BigDataAnalysis, Silicon Valley Data Science). One of the questions that was asked: “Who's more dangerous; A data scientist with poor domain knowledge or A domain expert with poor data science skills?". A more elaborate discussion can be found here (compiled by Robert Munro @idibon).

Wednesday morning started with a keynote talk by Dr. Hal Varian (Chief Economist at Google, see picture below) titled “Predicting the Present with Search Engine Data”. More specifically, he talked nowcasting using Bayesian Structural Time Series. It was nice to see that he is also a heavy R user (#Rstats). He mentioned the stl R package with many worked-out examples.
He talks about how machine learning and data mining along with randomized experiments were used to target and influence tens of millions of people. It is clear that predictive analytics could not make up several percentage points in the elections, but it did make a difference for states where both candidates were close.

Next, I attended the session on Web Mining. The research paper titled “Statistical Quality Estimation for General Crowdsourcing Tasks” by Yukino Baba (The University of Tokyo) and Hisashi Kashima (The University of Tokyo) was presented first.


Next, “Exploring Consumer Psychology for Click Prediction in Sponsored Search” was presented by Taifeng Wang, Jiang Bian, Tie-Yan Liu (Microsoft).


Finally, Simon Lacoste-Julien (INRIA / ENS) presented his talk titled “SiGMa: Simple Greedy Matching for Aligning Large Knowledge Bases”.





Next, all best papers were presented in a plenary session. Congratulations to all winners! Edo Liberty (@YahooLabs, see picture below) won the best research paper award with his single-authored paper titled “Simple and Deterministic Matrix Sketches".


The next award-winning best student paper was presented by Madhav Jha (Penn State, Sandia National Labs) titled “A space efficient streaming algorithm for triangle counting using the birthday paradox”.


Next, the best industry government paper was presented titled “Amplifying the voice of youth in Africa via text analysis” (Authors: Prem Melville, IBM Research; Vijil Chenthamarakshan IBM Research; Richard Lawrence, IBM Research; James Powell, UNICEF Uganda; Moses Mugisha, UNICEF Uganda; Sharad Sapra, UNICEF Uganda; Rajesh Anandan, US Fund for UNICEF; Solomon Assefa, IBM Research). This is a great application of text/data mining technology by UNICEF to help channel the right SMS message to the right department.



The best industry government paper Runner Up is titled “Query clustering based on bid landscape for sponsored search auction optimization” (Authors: Ye Chen, Microsoft; Weiguo Liu; Jeonghee Yi; Anton Schwaighofer; Tak Yan, Microsoft).



Finally, it was time to brainstorm what to improve about the KDD conference. The fact that very few items were raised was in fact a signal that this was a very good edition. Congratulations again to the organizers! A raffle at the very end of this session resulted in two new owners of these laptops.


See you all at KDD in New York City in August 2014. Below, you see yours truly (@dirkvandenpoel) at the conference venue as well as some pictures of beautiful Chicago. During and after the KDD conference @nodexl constructed an SNA map of tweets during the KDD 2013. They did a great job clustering tweeps/tweets. So what else did I learn about at this conference: 1. The “Data Science for Social Good” (@datascifellows) initiative: Click here for some pictures about their activities during KDD. 2. The job market is red hot for data scientists. Many of the companies were hiring (not just the ones that had a booth in the exhibit hall shown above): e.g. Netflix.







