SC13 Supercomputing Conference in Denver, CO

10,000+ computer scientists attended the largest supercomputing event in the world at the Colorado Convention Center in Downtown Denver organized by the sighpc of ACM and the IEEE CS (#SC13). Even with this record turnout, the organization did a flawless job! Congratulations! The highlights include a great keynote by Dr. Williams (D-Wave), an announcement by Intel to update their Xeon Phi 22 nm co-processor to a new 14 nm (bootable) version called Knights Landing. Moreover, NVIDIA announced the Kepler K40 graphics/co-processor. The many interesting talks about (big) data visualization was another highlight.
Friday 22 November 2013


This edition marked the 25th anniversary of the SC conference. The organizers compiled a fact sheet for every single edition as well as some overviews by specific topics, and posted them at the entrance of the convention center (see picture below).
On Sunday, Nov. 17, the conference started for me by following a tutorial about advanced MPI (Message Passing Interface) programming. Rajeev Thakur (Argonne National Laboratory, see picture below) discussed how to use MPI datatypes (MPI_Type_continguous, MPI_Type_Vector). He gave several specific example programs. Moreover, he discussed good practice to defer synchronisation (MPI_Waitall).



Next, James Dinan (Intel Corp, see picture below) explained one-sided communication (also called MPI RMA: remote memory access). The basic idea is to decouple data movement from process synchronization. The main advantage being that operations are non-blocking (MPI_Put, MPI_Get, MPI_Accumulate).

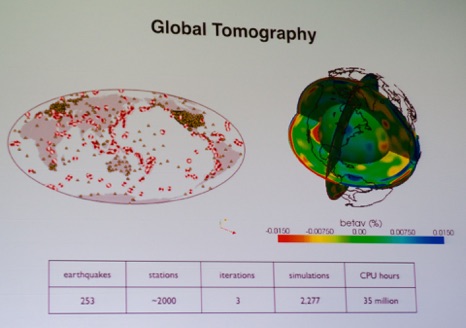
After lunch, I switched to the 4th SC Workshop on Petascale (Big) Data Analytics: Challenges and Opportunities. The first talk was by Matthieu Lefebvre (Princeton University, see picture below) on large-scale seismic imaging workflows.


Subsequently, I returned to the advanced MPI programming tutorial. Torsten Hoefler (ETH Zürich, see picture below) explained MPI topology (among other topics).

The next morning, Monday, Nov. 18, I attended the Python in HPC tutorial. The presentors included Andy Terrel (@aterrel, University of Texas at Austin, see pictures below), Travis Oliphant (@teoliphant, Continuum Analytics), Aron Ahmadia (@ContinuumIO, Continuum Analytics), Kurt Smith (@enthought, Enthought, Inc.). They discussed many interesting projects such as NumPy, SciPy, Matplotlib, SymPy, Pandas, Cython, Mayavi, mpi4py, and IPython.

Next, also before lunch, they discussed Cython (C-extensions to Python). In general, the organizers provided excellent facilities (sufficient fixed ethernet connectivity as well as great eduroam wireless + power sockets).


A lunch was offered to those who registered for the SC13 tutorials (see picture below).

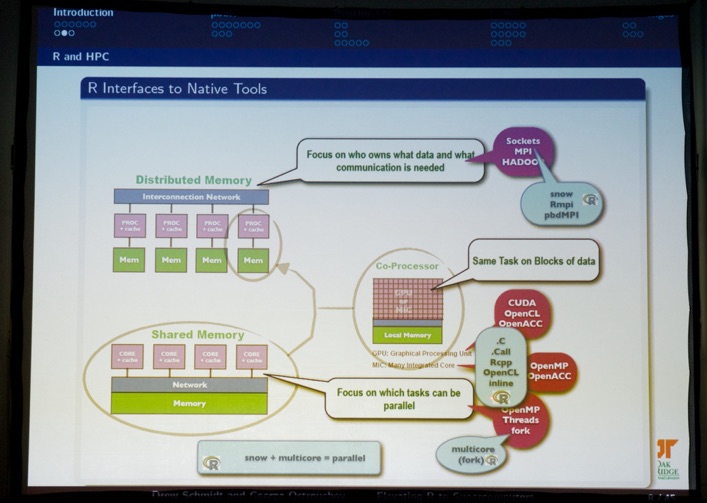
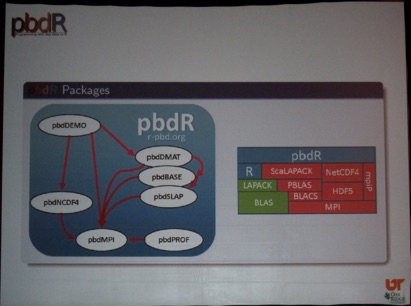
In the afternoon, I switched to the “R: From your Laptop to HPC and Big Data” session by Drew Schmidt (University of Tennessee) and George Ostrouchov. Because yours truly (@dirkvandenpoel) also started using R for teaching my “Predictive and Prescriptive Analytics” course in www.mma.UGent.be and www.me.UGent.be, this was a highly relevant topic. They gave a superb talk about their pbdR package, which enables distributed computation of matrix operations.


That evening, the huge exhibit floor opened to the 10,000+ attendees. Lots of well-known universities, companies, and research institutes were present on the show floor including (see pictures below): @PRICE_RI, @FraunhoferITWM (they offered great free coffee), @TACC, @IntelHPC, @IBM, @NVIDIA, @ARM, among many others.









The NASA booth displayed a quantum processor (@NASA, see picture below).



Tuesday, Nov. 19 started off with a keynote presentation titled “The Secret Life of Data” by Dr. Genevieve Bell (@feraldata, Intel Fellow). She gave many examples about the value of data: The first example is the Domesday book. Next, she discussed the value of visualizations.

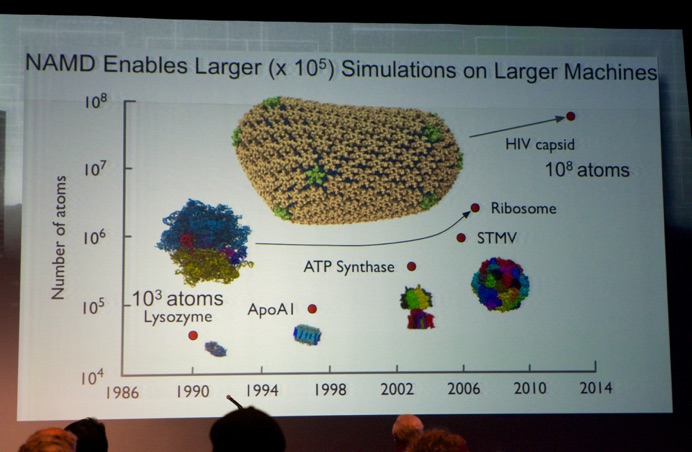
Next, Prof. Dr. Klaus Schulten (University of Illinois Urbana-Champaign, see picture below) took the stage for the first invited talk on “The State of Extreme-Scale Molecular Dynamics (in Computational Biology)”. He explained how they use computational models to explain how drugs attack viruses (e.g. interfere in the communication, acting as a con-artist).



Next, Prof. Dr. Takashi Furumura (Earthquake Research Institute, University of Tokyo, see picture below) presented a great keynote speech on the topic of “Visualization of Strong Ground Motion and Tsunami for the Great Earthquake of 2011 Off Tohoku, Japan”.
Several years ago, the Kobe earthquake was analyzed in great detail. This led to the installation of many more sensors across the entire country. The outcome was a prediction of a M7.5 earthquake in the area off Tohoku. It happened, but was much stronger: In 2011 a magnitude 9.0 earthquake off Tohoku took place. Thanks to the many sensors, very detailed measurements were available. As a result of having better data, Japanese researchers were able to create a compound ground motion and tsunami simulation (instead of separate ones)! After building the prediction models, they then applied it to the likely new earthquakes…


Next, I walked the show floor again. Japanese universities and research institutes had a strong presence in Denver.


After lunch, I attended the Awards ceremony. Prof. Dr. Jack Dongarra (University of Tennessee) received the Ken Kennedy Award. He gave an acceptance speech sharing many interesting ideas and anecdotes in his career.


The NAIST (Nara Institute of Science and Technology, see picture below) showed a video documenting the interesting concept of placing HPC equipment in containers. They have two such HPC installations in production.
Next, Prof. Dr. Marc Snir (University of Illinois, Urbana-Champaign) gave his acceptance speech for the IEEE Computer Society Seymour Cray Computer Engineering Award (@ComputerSociety).




Finally, Prof. Dr. Chris Johnson (University of Utah) accepted the IEEE CS Fernbach Award for his visualization Institute.


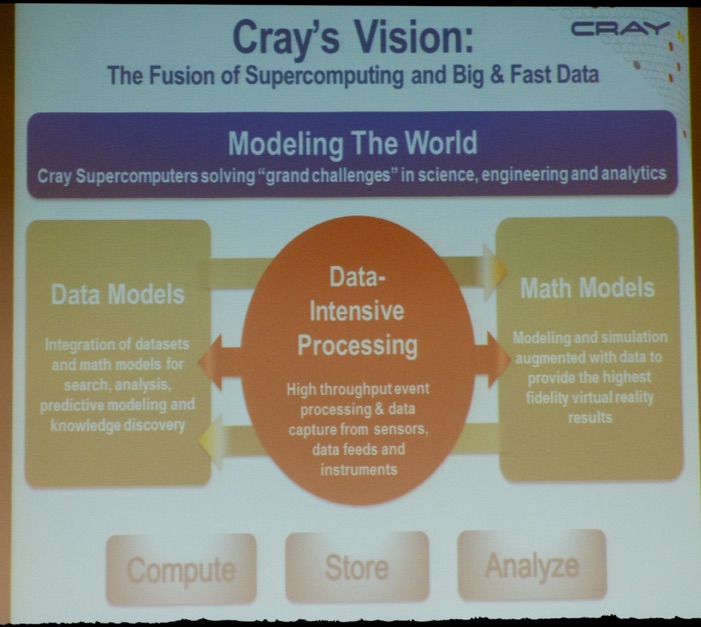
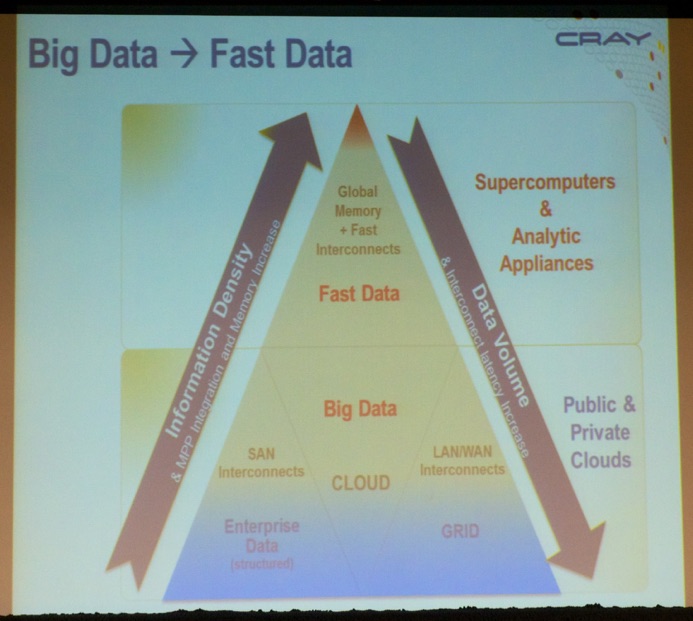
Next, I attended the European Cray meeting. Cray CEO (@Cray_Inc), Peter Ungaro (see picture below), discussed the highlights of their strategy: The fusion of Supercomputing and Big Data.



Wednesday, November 20, 2013 I first attended the SGI Innovator Breakfast meeting. After an introduction by both the CEO of SGI (Jorge Titinger, @SGI_Corp) and CMO (Bob Braham) - during which they both emphasized that SGI is winning big contracts again after some “difficult” years - they invited Rajeeb Hazra (Intel VP and GM of Technical Computing Group, @IntelITS). He discussed Intel’s vision on the paradigm shift from supercomputing to Big Data.

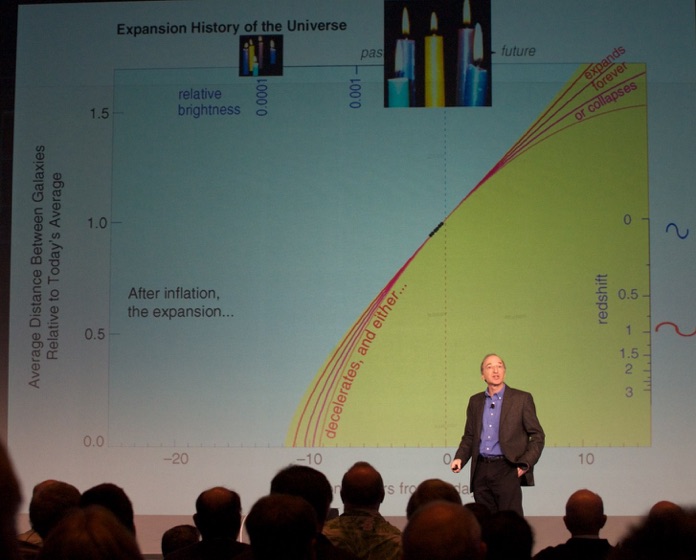
Next, I rushed to the Colorado Convention Center. Prof. Dr. Saul Perlmutter (Professor at UC Berkeley @BerkeleyLab & astrophysicist at Lawrence Berkeley National Laboratory, see picture below) delivered his keynote talk. He basically updated us on what has happened between his talk at SC98 and today.







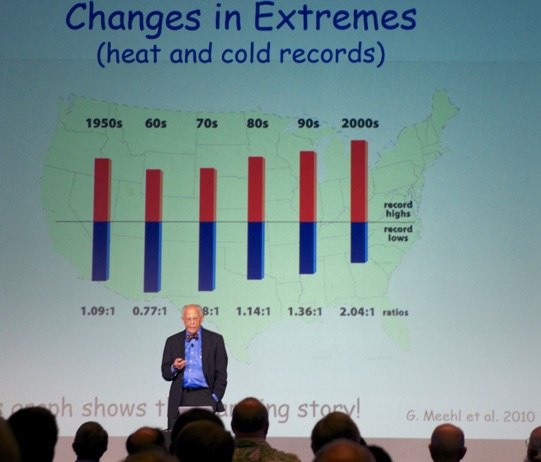
Next, Dr. Warren Washington (National Center for Atmospheric Research) took the stage for his talk titled “Climate Earth System Modeling for the IPCC Sixth Assessment Report (AR6): Higher Resolution and Complexity” showing the evidence for global warming.
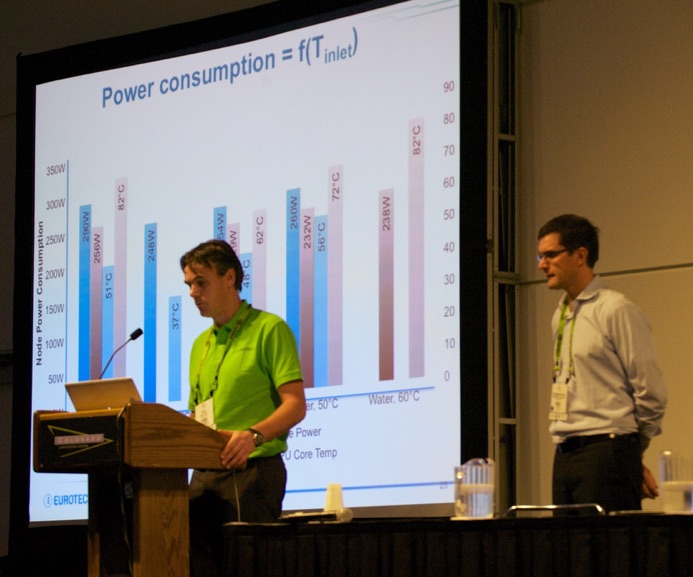
After lunch, I attended the Exhibitor Forum presentation session. First, Eurotech engineers (including Giovanbattista Mattiussi) took the stage to discuss energy-efficient HPC systems (@EuroTechHPC).
They argued that obtaining high energy efficiency from standard components is a matter of architectural decisions and design capable of optimizing the contribution of accelerators, liquid cooling and power conversion to maximize efficiency.
Next, Alexander Moskovsky (RSC Group, see picture below) gave his talk “A Practical Approach to Exascale – a New RSC’s Ultra High Density Solution with Intel® Xeon Phi™”. RSC Group (www.rscgroup.ru/en), a developer of direct liquid cooling technologies for HPC and supercomputing
systems, announced a new product at SC13: a new ultra-high density, energy efficient solution
with Intel Xeon Phi coprocessors.


Finally, William Blake (Cray Inc., @CRAY_Inc, see picture below) gave his presentation “Map to Discovery: Data-Intensive Course”.

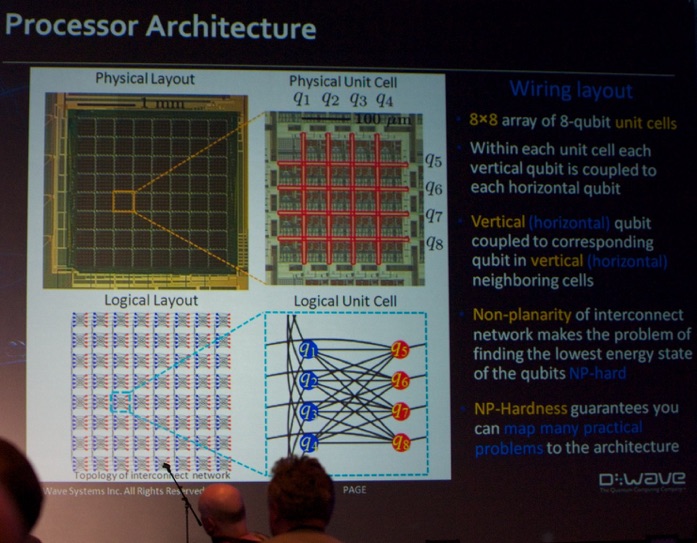
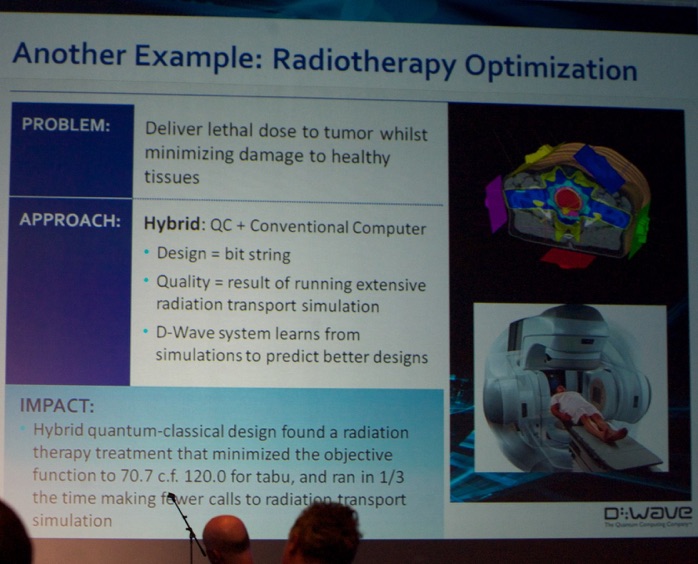
Next, I attended the keynote talk by Dr. Colin P. Williams (@DWaveSys, D-Wave Systems) on Quantum Computing. This was - in my humble opinion - probably the best talk of the entire SC13 conference.
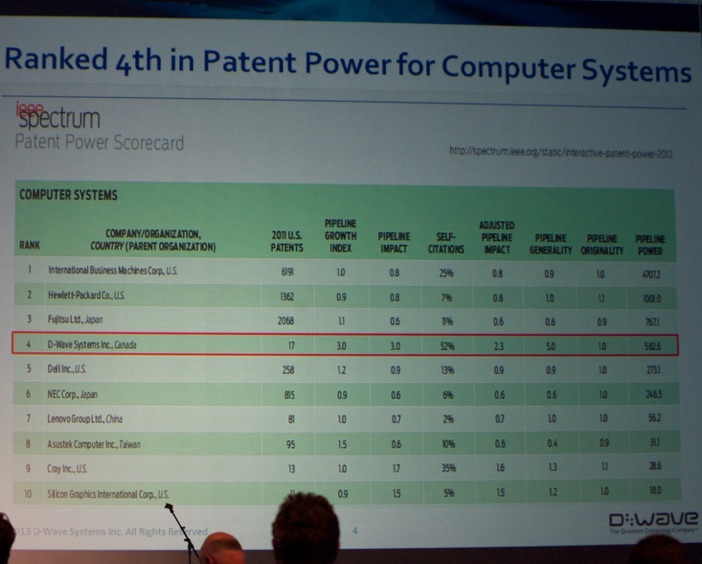
It is quite remarkable for a 100-employee company to rank 4th in terms of patents among all companies worldwide.
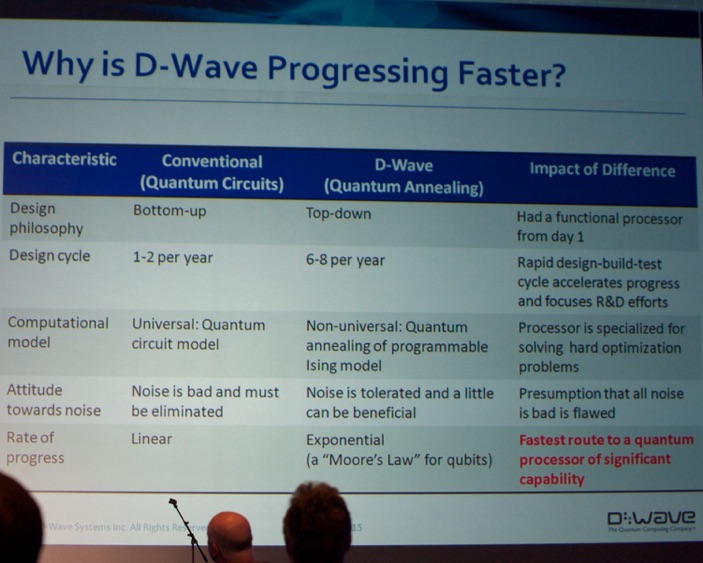
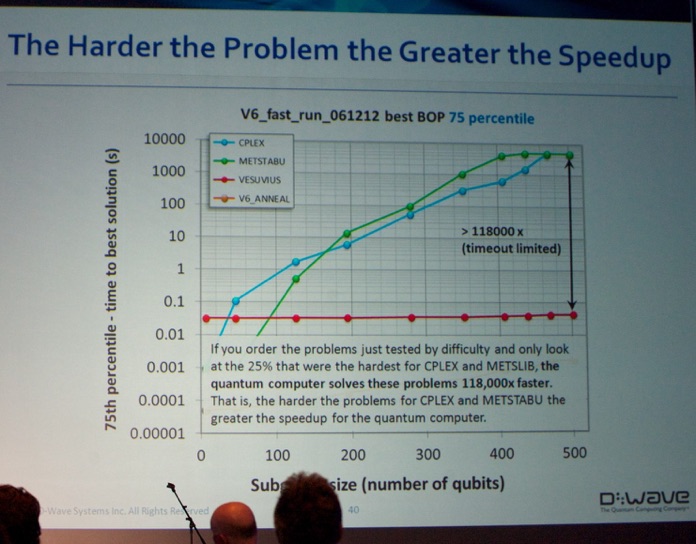
Instead of building a “generic” quantum computer they chose to build a machine to tackle specific well-defined tasks. He mentioned that they engineered a system to solve NP-hard optimization problems of size 2^512. This can be used to do discrete combinatorial optimization, which performed 118000x faster than Cplex (in some applications). Google used the system for building better ensemble binary classifiers (a task very near and dear to our heart: see www.datamining.UGent.be).





In late-afternoon, I attended the Super-R (#rstats) BOF (Birds-of-a-feather) session. This is basically a gathering of like-minded computer scientists/engineers. It was a well-attended session. They first started by talking about using R on supercomputers (e.g. @TACC #XSEDE). Next, they proceeded to discussing use cases of using R for larger datasets. One cool example was: performing a linear regression on 24,000 cores on 1 TB of data with 2000 predictors in 2 minutes (Benchmark on Kraken without GPUs). They also showed how to use Intel Xeon Phi with R to achieve a speedup of up to 60x using Xeon Phi compared to one-threaded (off-loading using MKL).


Wednesday evening, I joined the Mellanox event. Hundreds of attendees joined Eyal Waldman (CEO at @Mellanoxtech, see picture below). He highlighted the recent achievements in the area of Infiniband Interconnects: e.g. their Connect-IB™ FDR 56Gb/s InfiniBand adapter. He also highlighted the (long-distance) RDMA developments, including those with GPUs.

Next, Bob Galush (VP IBM System x high volume servers, @IBMSysXBlade, see picture below) took the stage during the Mellanox event. He discussed how IBM and Mellanox InfiniBand integrate to form powerful supercomputers.

The final talk of the day was by Bob Ciotti (Chief Architect and System Lead for Supercomputing NASA Advanced Supercomputing Division - NASA Ames Research Center, @NASA_NAS). He discussed the different upgrade cycles NASA went through in their supercomputing center.



Thursday morning started off with a talk by Prof. Dr. Alok Choudhary (Northwestern University, see picture below) titled “BIG DATA + BIG COMPUTE = An Extreme Scale Marriage for Smarter Science?”


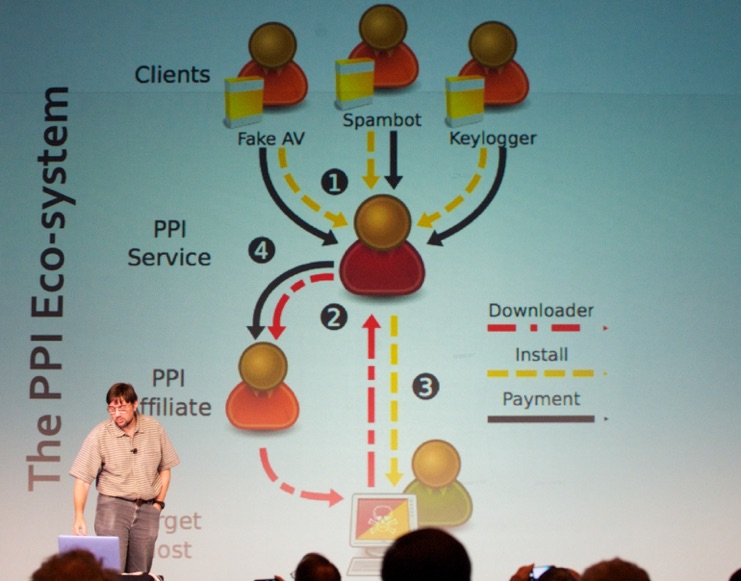
Next, Prof. Dr. Vern Paxson (University of California, Berkeley, see picture below) took the stage with a talk titled “The Interplay Between Internet Security and Scale”.

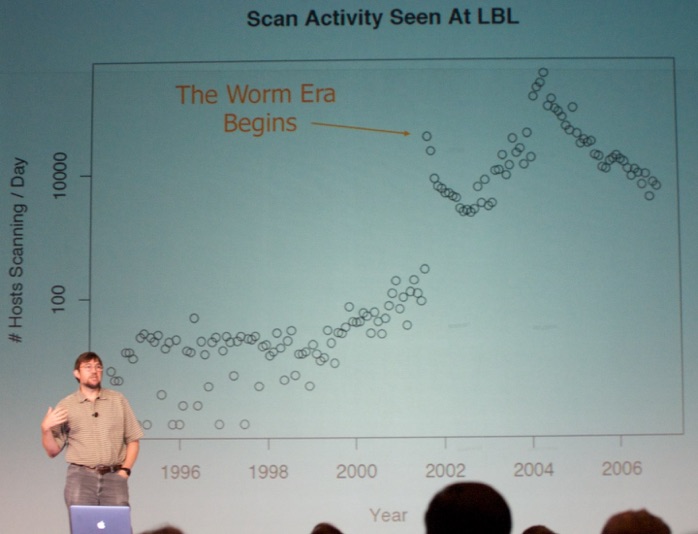
He did a great job in outlining how the scams work. Then, he discussed how they were able to infiltrate the systems to combat them.

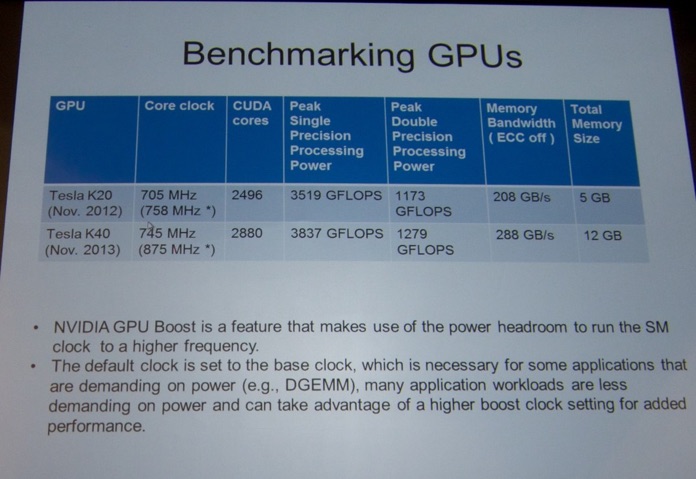
Next, I attended a vendor-sponsored talk at the NVIDIA booth. They presented benchmarks with the new Tesla K40 GPU.
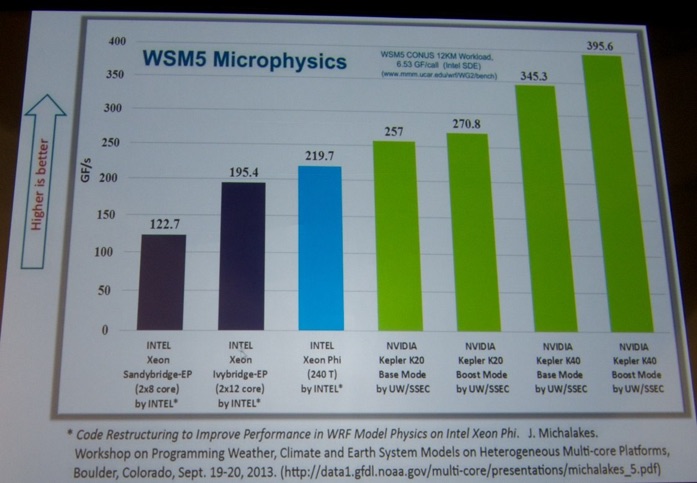
Throughout the conference, interesting posters - such as the one shown below - were displayed.


That afternoon, I also took the Intel Tour on the show floor. It’s an interesting concept: Intel walks a group of attendees to some of its partner companies.


That evening the SC13 conference dinner took place in the Denver Science Museum.


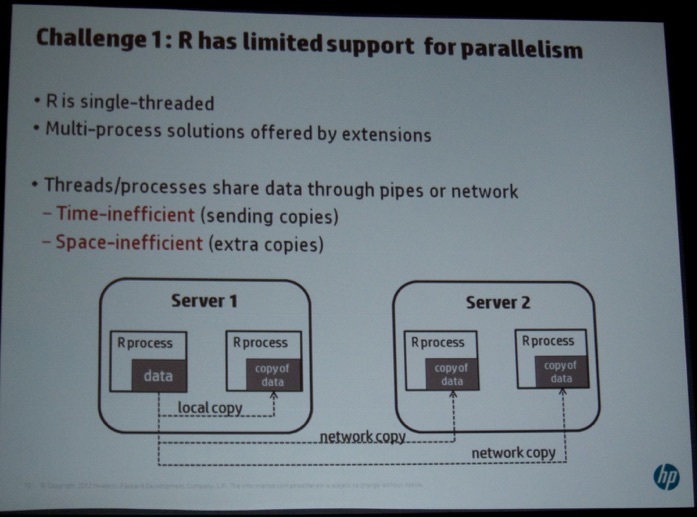
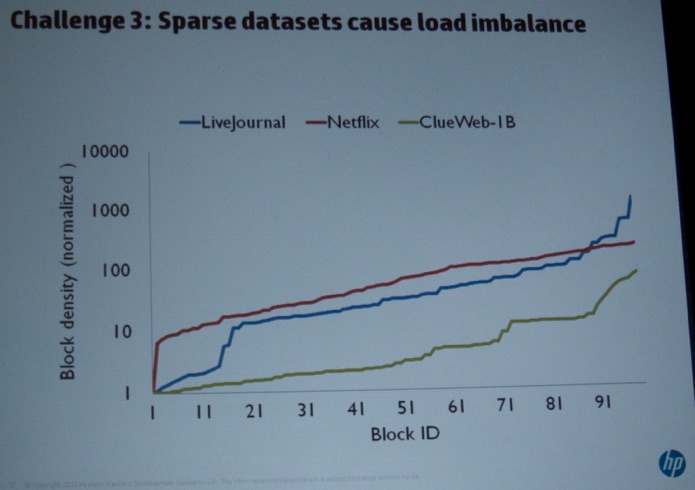
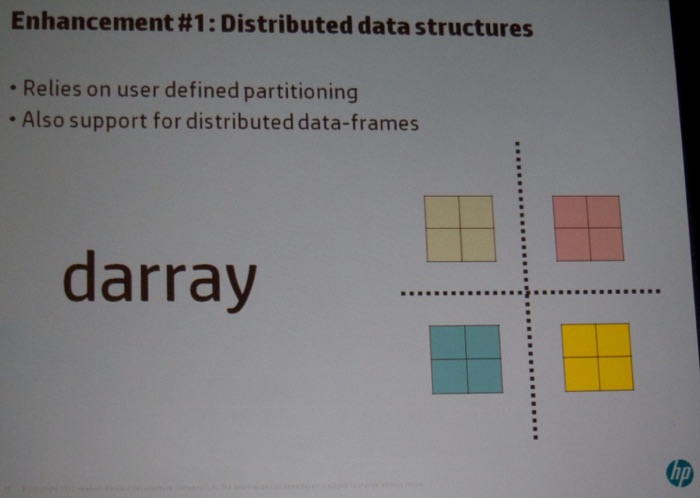
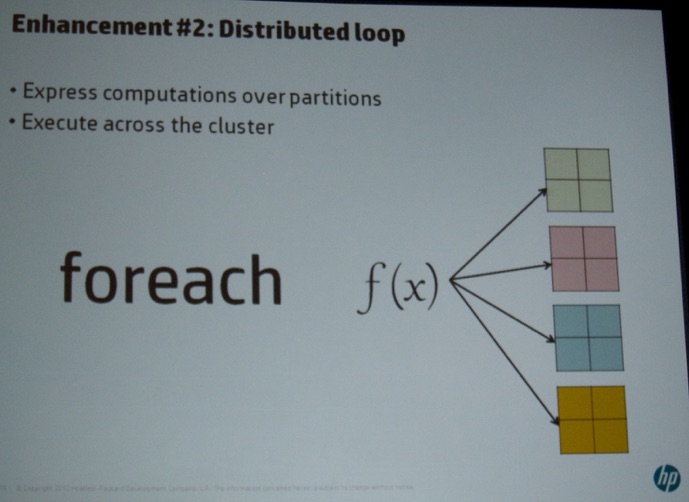
On Friday, I attended the Workshop on Large-Scale Data Analytics (LSDA). Indrajit Roy (HP, see picture below) kicked off the session with a very interesting talk titled “Distributed R for Big Data”. He discussed several challenges in “standard” R. Next, he discussed the enhancements they proposed (see pictures below).




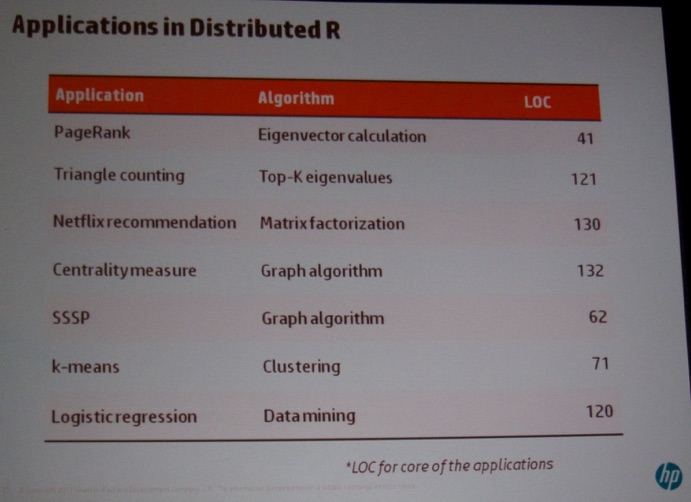
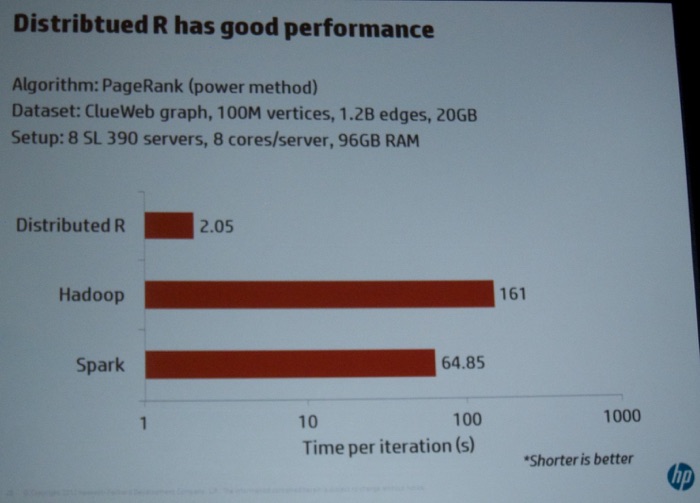
Next, Mostofa Ali Patwary (Intel Labs, see picture below) presented his talk “Scalable Parallel Density-based Clustering”, detailing a new parallel DBSCAN algorithm.


Next, Archana Ganapathi (Splunk, @Splunk, see picture below) gave a talk “Real-time Insights and Analytics on Bid Data”. She discussed their big data tool and presented use cases.

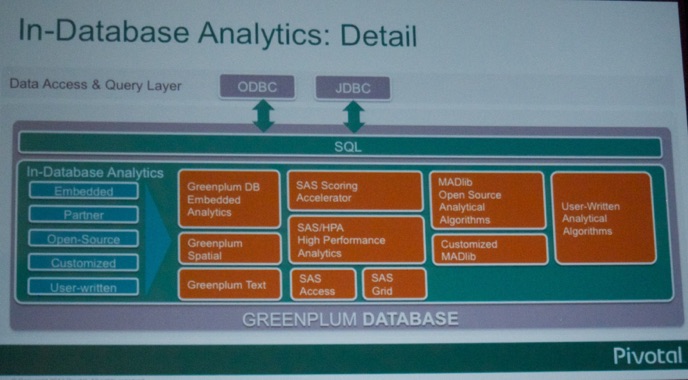
After the break, Kaushik Das (@kaushiksf at @GoPivotal, see picture below) talks data analytics. A very interesting presentation about the software stack Pivotal is using!

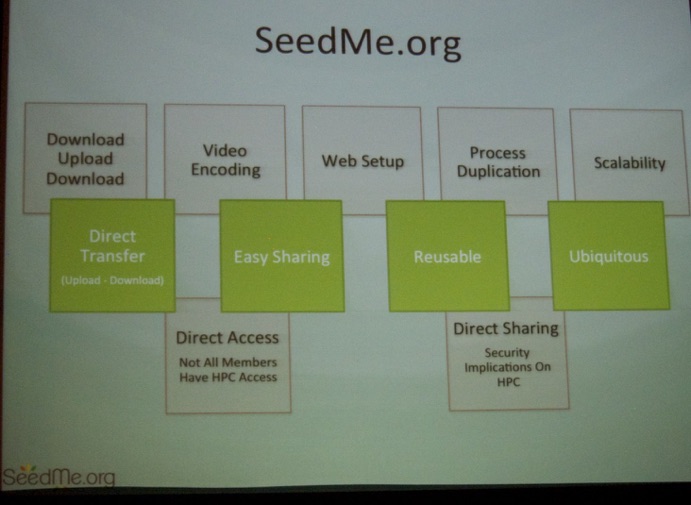
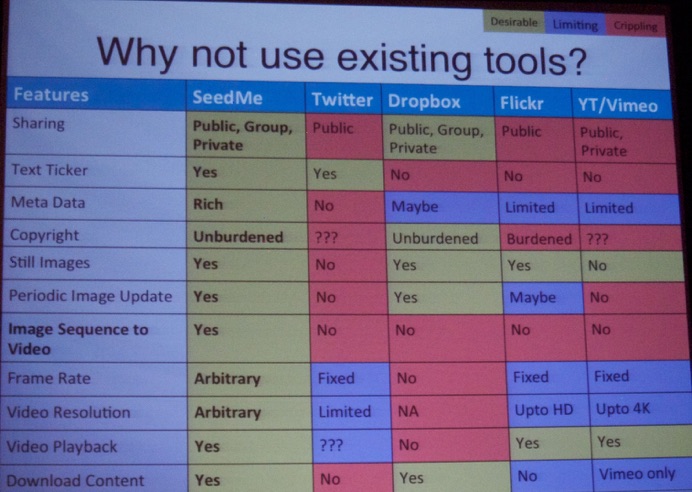
Next, Amit Chourasia (SDSC, see picture below) talked SeedMe.org: A free infrastructure for researchers to share results.


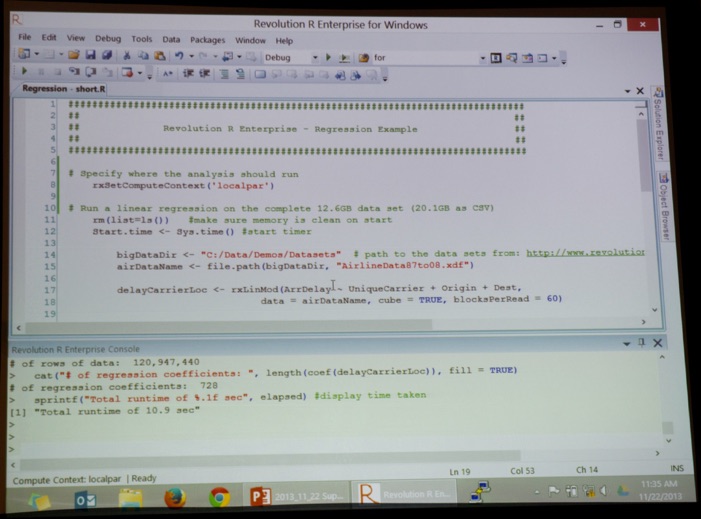
Finally, Michael Helbraun (Revolution Analytics, @RevolutionR, see picture below) took the stage for his presentation “Big Data Big Analytics: State of the Industry”.


The Workshop on Large-Scale Data Analytics (LSDA) ended with an interesting panel discussion.

Then, I had to rush to the airport to catch my flight back home. In sum, SC13 was a GREAT event. See you all in New Orleans for SC14.
